 無題Name名無し24/06/20(木)10:19:51No.71055+
15日00:40頃消えます
無題Name名無し24/06/20(木)10:19:51No.71055+
15日00:40頃消えます
質問スレ削除された記事が13件あります.見る
| … | 1無題Name名無し 24/06/22(土)13:27:02No.71623+リートンでどんなプロンプトも拒否されるようになった |
| … | 2無題Name名無し 24/06/22(土)17:00:27No.71681そうだねx1pixaiでCivitaiからモデルを導入するってボタンがあったから、使いたいLoRAを追加したんだけど、もしかしてこれって無断転載だったのかな? |
| … | 3無題Name名無し 24/06/23(日)01:38:28No.71771+会社同士では話付いてるんじゃないの? |
| … | 4無題Name名無し 24/06/23(日)15:13:16No.71899+loraって体の一部のみを学習させるのってあるかな |
| … | 5無題Name名無し 24/06/23(日)15:22:12No.71901+>loraって体の一部のみを学習させるのってあるかな |
| … | 6無題Name名無し 24/06/23(日)16:05:05No.71907+特定キャラLoRAで顔や髪型を保持したまま色んな服を着せ変えたりロリ化できるやつも言ってみれば「体の一部」を学習してることになるのかな |
| … | 7無題Name名無し 24/06/23(日)19:56:06No.71964+ 1719140166612.jpg-(58895 B)  PixaiにLoraを導入するとき「そのLoraは導入済みです」って言われることがあって |
| … | 8無題Name名無し 24/06/23(日)20:24:22No.71968+>No.71623 |
| … | 9無題Name名無し 24/06/23(日)20:25:43No.71969+>もしかして先に他人が個人用に登録してあるLoraも導入済みにカウントされるのかな |
| … | 10無題Name名無し 24/06/23(日)20:35:46No.71971+>非公開ならないと思う |
| … | 11無題Name名無し 24/06/24(月)09:09:48No.72088+としあきdiffusion WikiのComfyUI・ノード作るとか面倒なのでなんとかしてよでダウンロードできるt2i_i2i.json |
| … | 12無題Name名無し 24/06/24(月)20:57:21No.72208+今までPixAIでしかやった事なかったんだけど |
| … | 13無題Name名無し 24/06/25(火)03:29:51No.72297+無料分(100クレジット)でやったら学習元データが5枚しか使えなかったですよ |
| … | 14無題Name名無し 24/06/25(火)12:42:16No.72371+>loraって体の一部のみを学習させるのってあるかな |
| … | 15無題Name名無し 24/06/25(火)23:07:54No.72446+yodayoの生成結構便利じゃん |
| … | 16無題Name名無し 24/06/25(火)23:43:06No.72455+Tensorの使ってみたけど学習枚数5枚でもそれっぽいのできるし |
| … | 17無題Name名無し 24/06/26(水)09:24:03No.72528+novelaiで事後絵を量産してるんだけど「新しいティッシュを箱から引き抜く」「ティッシュで股間を拭く」が出ない… |
| … | 18無題Name名無し 24/06/26(水)18:42:41No.72614+>無料分(100クレジット)でやったら学習元データが5枚しか使えなかったですよ |
| … | 19無題Name名無し 24/06/26(水)18:58:09No.72618+PixAIのLoRA生成ってどんなもんなんだろ |
| … | 20無題Name名無し 24/06/26(水)20:10:11No.72626そうだねx2>novelaiで事後絵を量産してるんだけど「新しいティッシュを箱から引き抜く」「ティッシュで股間を拭く」が出ない… |
| … | 21無題Name名無し 24/06/26(水)21:09:32No.72634+>例えば「股間を拭く」ではなく「手が股にある。白い布を手で持っている」みたいな |
| … | 22無題Name名無し 24/06/27(木)00:52:26No.72678そうだねx1>で、目的のシチュを表すタグがどうもなさそうだったら自然言語でそのシーンをどう表現するかを考える |
| … | 23無題Name名無し 24/06/27(木)20:08:23No.72775+ebara pony用のLoRA作る時って学習自体は |
| … | 24無題Name名無し 24/06/27(木)21:05:09No.72786+TensorArtにLoRAを上げる際に |
| … | 25無題Name名無し 24/06/27(木)22:15:55No.72801+ 1719494155529.jpg-(12302 B)  >サイズは「Full」と「Pruned」浮動小数点は「fp16」と「fp32」の |
| … | 26無題Name名無し 24/06/28(金)04:11:59No.72849+ 1719515519213.png-(15659 B)  >どうだったかな |
| … | 27無題Name名無し 24/06/28(金)05:10:08No.72853+ 1719519008601.png-(6451 B)  >一通り組み合わせを試したんですがこの表示から抜けられなかったです |
| … | 28無題Name名無し 24/06/28(金)12:43:31No.72899そうだねx1 1719546211386.jpg-(237491 B)  質問1と2 |
| … | 29無題Name名無し 24/06/28(金)12:45:35No.72900+ 1719546335246.jpg-(221010 B)  画像② |
| … | 30無題Name名無し 24/06/28(金)17:48:00No.72938+stable diffusion forgeでlycorisって統合?されて区別なくLoraから使えてたんだけど |
| … | 31無題Name名無し 24/06/28(金)21:18:10No.72973+forgeでPonyでHyper-SDXL使って |
| … | 32無題Name名無し 24/06/29(土)07:50:15No.73033+LoRA作る人はネガティブプロンプトなしでテストして欲しい… |
| … | 33無題Name名無し 24/06/29(土)07:54:08No.73034+>No.72973 |
| … | 34無題Name名無し 24/06/29(土)17:12:40No.73100+>質問1と2 |
| … | 35無題Name名無し 24/06/30(日)08:16:39No.73209+立派なちんちんが(内臓とか頭蓋骨とか細かいこと抜きにして)根元までずぼっと入ってる、を再現できるフレーズってないもんでしょうか |
| … | 36無題Name名無し 24/06/30(日)08:24:45No.73210そうだねx4一応、ものすごく一般論としては、ちんちんの大部分が挿入等で見えないならプロンプトでpenisと「書いてはいけない」 |
| … | 37無題Name名無し 24/06/30(日)09:30:27No.73219+>元画像のタグ付けが厳密かどうかにもよるんだけど… |
| … | 38無題Name名無し 24/06/30(日)09:31:41No.73220+>No.73219 |
| … | 39無題Name名無し 24/06/30(日)17:52:39No.73307+>>質問1と2 |
| … | 40無題Name名無し 24/06/30(日)22:17:57No.73358+>No.73209 |
| … | 41無題Name名無し 24/07/01(月)21:19:10No.73521そうだねx1 1719836350711.png-(2437 B)  seaartのSDXLの項目にあるRefinerって何なんでしょうか |
| … | 42無題Name名無し 24/07/01(月)21:55:18No.73534+SDXLにはbaseモデルとrefinerモデルがあり…という話が必要なんだろうか |
| … | 43無題Name名無し 24/07/01(月)22:21:38No.73538+ponyマージモデルと対応LoRAがしびたいで毎日100個くらいじゃんじゃこ投稿される未来を予知してたらこうはならなかったとは思う |
| … | 44無題Name名無し 24/07/01(月)23:25:55No.73549そうだねx2 1719843955347.png-(673521 B)  deep penetration,プロンプトおもろいな。上半身視点のタグでも明らかに反応が突っ込んだ後のものになる。 |
| … | 45無題Name名無し 24/07/02(火)06:14:34No.73579+>SDXLにはbaseモデルとrefinerモデルがあり…という話が必要なんだろうか |
| … | 46無題Name名無し 24/07/02(火)08:23:28No.73596+SDは行為と表情は分けることができるので適当に表情だけ行為中にするといいぞ |
| … | 47無題Name名無し 24/07/02(火)08:30:02No.73602+close-upつきでlow angle viewの連続生成をすると |
| … | 48無題Name名無し 24/07/02(火)09:56:16No.73612+>質問1と2 |
| … | 49無題Name名無し 24/07/02(火)10:21:32No.73618+>seaartのSDXLの項目にあるRefinerって何なんでしょうか |
| … | 50無題Name名無し 24/07/02(火)17:45:11No.73653+昔配布してたとしあきbat使ってlora作ってたんだけどSDXL環境でも設定書き換えたらちゃんと作れるのかしら |
| … | 51無題Name名無し 24/07/02(火)22:41:51No.73713+>>No.73596 |
| … | 52無題Name名無し 24/07/03(水)18:07:41No.73816+>>質問1と2 |
| … | 53無題Name名無し 24/07/05(金)22:48:48No.74161+チェックポイントは絵柄・画風 |
| … | 54無題Name名無し 24/07/05(金)23:43:38No.74178そうだねx1>という認識で合ってる? |
| … | 55無題Name名無し 24/07/06(土)06:28:57No.74228そうだねx2 1720214937410.png-(662872 B)  >>No.74161 |
| … | 56無題Name名無し 24/07/06(土)07:03:41No.74233そうだねx1 1720217021822.png-(1491544 B)  PixAI に一応LoRA 学習機能あるけどもしかしてロリキャラであることは意図的に学習しないような設定になってるのかな? |
| … | 57無題Name名無し 24/07/06(土)08:20:26No.74241そうだねx1loliという単語そのものを面倒くさがって弾くサイトは多い |
| … | 58無題Name名無し 24/07/06(土)10:01:54No.74265+>No.74228 |
| … | 59無題Name名無し 24/07/06(土)11:37:06No.74273+>>No.74265 |
| … | 60無題Name名無し 24/07/06(土)11:37:48No.74274+・・・続き |
| … | 61無題Name名無し 24/07/06(土)11:58:34No.74276+、、、とりあえず一言で表すと、Loraはガンガン差し込むと危険だが、enbeddingはガンガン差し込んでも問題ない。 |
| … | 62無題Name名無し 24/07/06(土)14:26:20No.74306そうだねx1え?何…お前すごいな…ありがとう |
| … | 63無題Name名無し 24/07/06(土)17:23:21No.74326+とはいえ、今どきembeddingでキャラや構図作る人はだいぶ減ったんだよなぁ |
| … | 64無題Name名無し 24/07/06(土)17:58:01No.74332+pony系やXL系のCheckpointがembedding不要なレベルで強力ってのも廃れ始めてる理由やね。SD1.5あたりのCheckpointではまだまだなきゃ困る。 |
| … | 65無題Name名無し 24/07/06(土)19:17:37No.74336+embeddingで制御するにはXL空間は広すぎる |
| … | 66無題Name名無し 24/07/06(土)19:22:40No.74338+>No.74336 |
| … | 67無題Name名無し 24/07/06(土)19:38:42No.74342+22年の夏〜年末くらいのうろ覚えな記憶だけど、 |
| … | 68無題Name名無し 24/07/07(日)09:40:00No.74408+他の人が生成した画像保存のサイトありますか |
| … | 69無題Name名無し 24/07/07(日)11:39:08No.74440+>>No.74408 |
| … | 70無題Name名無し 24/07/07(日)11:48:22No.74441+みんなどうやってプロンプト管理してる? |
| … | 71無題Name名無し 24/07/07(日)16:41:44No.74494+プロンプトを使いまわしたいお気に入りのフォルダに生成物を分けといて |
| … | 72無題Name名無し 24/07/07(日)16:53:19No.74499+A1111とかForgeなら、styleに登録して呼び出してる。 |
| … | 73無題Name名無し 24/07/07(日)18:34:30No.74525+回答サンクス。やっぱみんな stable diffusion 上でプロンプト制作してるんやな。プロンプト編集ツールとしてはいまいち使いづらいんでメモ帳でプロンプト作成してそれを stable diffusion に張り付けるスタイルに落ち着いて、それが一番時短になってるんだが、、、。 |
| … | 74無題Name名無し 24/07/07(日)21:07:26No.74556+ 1720354046430.png-(193238 B) 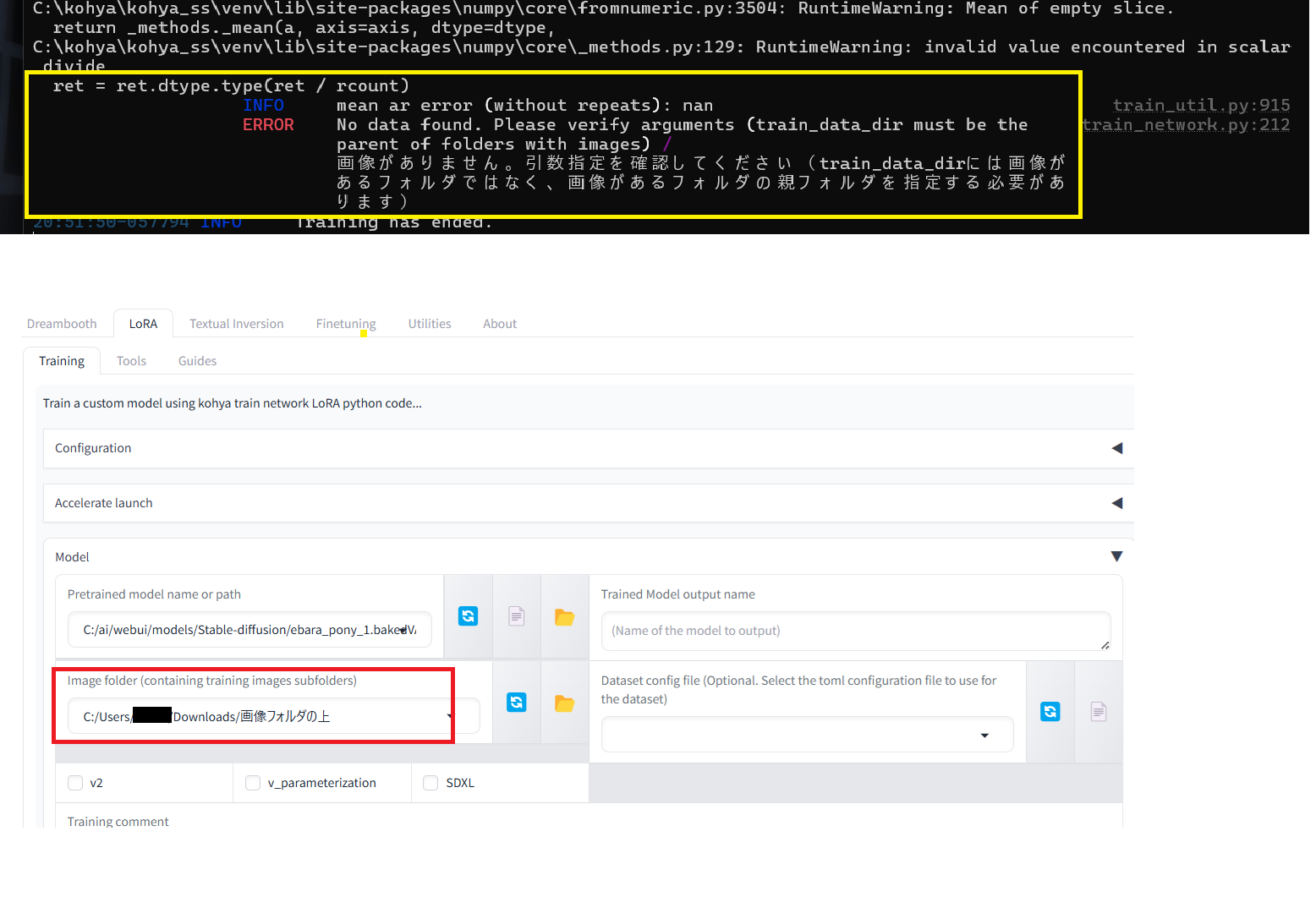 Kohya_ssについて質問です |
| … | 75無題Name名無し 24/07/07(日)21:32:01No.74559+>No.74441 |
| … | 76無題Name名無し 24/07/07(日)22:28:40No.74567+>No.74556 |
| … | 77無題Name名無し 24/07/08(月)03:51:59No.74609+ 1720378319263.jpg-(34499 B)  >みんなどうやってプロンプト管理してる? |
| … | 78無題Name名無し 24/07/08(月)04:58:14No.74616+テキストの解釈部分がAI的に進歩すれば自然言語的にできるだろうけど |
| … | 79無題Name名無し 24/07/08(月)08:23:30No.74647+少なくとも今の状況では自然言語的にはできないと思うなあ |
| … | 80無題Name名無し 24/07/08(月)14:17:10No.74686+SDも本来は自然言語でプロンプトを指示するものなんだけど |
| … | 81無題Name名無し 24/07/08(月)15:06:21No.74691+いや、「人間側が」絵を自然言語でうまく説明できないんだよ |
| … | 82無題Name名無し 24/07/08(月)20:08:42No.74729+SDXLの画像1枚作るの何秒くらいかかりますか? |
| … | 83無題Name名無し 24/07/08(月)20:21:29No.74732+30stepに10分かかるって言ってみんなに夢と希望を持たせるお仕事をおじさんはしてるんだよ |
| … | 84無題Name名無し 24/07/08(月)21:33:01No.74742そうだねx21枚5分を超すと、生成であれこれ試してみたい欲がどんどん削れていくようになってやばい |
| … | 85無題Name名無し 24/07/08(月)22:14:05No.74750+ユーザーが入力送信したプロンプトそのものってどこかに残ったりしてませんでしょうか |
| … | 86無題Name名無し 24/07/08(月)22:17:24No.74751+>No.74750 |
| … | 87無題Name名無し 24/07/08(月)22:20:16No.74752+そうですか… |
| … | 88無題Name名無し 24/07/08(月)22:33:21No.74755+ComfyUIだと流出事故レベルで全部画像に埋め込まれてるぞ |
| … | 89無題Name名無し 24/07/08(月)23:24:07No.74771そうだねx1>>No.74609 |
| … | 90無題Name名無し 24/07/09(火)02:27:38No.74792+初めてLora作りに挑戦してみたけど出来たLora使ったところ破綻どころか一面の青や橙のもやで何が悪かったのかさえ分からない |
| … | 91無題Name名無し 24/07/09(火)04:47:09No.74800+>No.74792 |
| … | 92無題Name名無し 24/07/09(火)09:56:17No.74835+>No.74792 |
| … | 93無題Name名無し 24/07/09(火)18:40:24No.74880+>No.74800 |
| … | 94無題Name名無し 24/07/09(火)19:14:51No.74886+loraの強度を下げて意味のある画像が出てきたとき |
| … | 95無題Name名無し 24/07/09(火)23:10:38No.74933+>画像フォルダの名前に繰り返し回数入れてますか? |
| … | 96無題Name名無し 24/07/10(水)01:38:45No.74964そうだねx1実写版のNAIみたいなサービスって何かある? |
| … | 97無題Name名無し 24/07/13(土)11:39:32No.75495+比較用のxyz plotで出力した画像を切り離して個別に保存する方法あるかな? |
| … | 98無題Name名無し 24/07/13(土)15:24:41No.75516そうだねx1デフォルトなら、txt2img-imagesのフォルダに入ってない? |
| … | 99無題Name名無し 24/07/13(土)22:15:55No.75576そうだねx1てか順番としては逆だな |
| … | 100無題Name名無し 24/07/14(日)01:26:54No.75627そうだねx1>実写版のNAIみたいなサービスって何かある? |
| … | 101無題Name名無し 24/07/14(日)09:33:47No.75681+>No.75516 |
| … | 102無題Name名無し 24/07/14(日)15:05:07No.75730+AIイラスト用にPC買い換えたいんだけどメモリはDDR5の方が良いの? |
| … | 103無題Name名無し 24/07/14(日)18:44:27No.75774+dynamic pronptがBatchCountやBatchiSizeで複数枚連続生成とすると機能してないっぽいんだけどどうやったら治るんだろうか? |
| … | 104無題Name名無し 24/07/14(日)19:39:17No.75780そうだねx1>No.75730 |
| … | 105無題Name名無し 24/07/14(日)20:17:57No.75791+Dynamic Promptsが動作するのはtorch.compileとか使ってない環境なんじゃないかなあ |
| … | 106無題Name名無し 24/07/14(日)20:38:55No.75793+>No.75780 |
| … | 107無題Name名無し 24/07/15(月)04:10:48No.75863+>>実写版のNAIみたいなサービスって何かある? |
| … | 108無題Name名無し 24/07/15(月)08:06:13No.75880+>Dynamic Promptsが動作するのはtorch.compileとか使ってない環境なんじゃないかなあ |
| … | 109無題Name名無し 24/07/15(月)18:05:21No.75945+dynamic promtはbatch countいじったところで無効にはならん |
| … | 110無題Name名無し 24/07/15(月)18:41:25No.75955+>>No.75774 |
| … | 111無題Name名無し 24/07/15(月)18:53:33No.75959+Stable Diffusionで低い解像度で生成してるけど、あとからhires.fixでアップスケーリングする方法とかある? |
| … | 112無題Name名無し 24/07/15(月)19:22:53No.75966そうだねx1hires.fixは「1回目の生成画像を捨てて最初から大きい画像のフリをして出すimage2image」なので、 |
| … | 113無題Name名無し 24/07/15(月)21:55:17No.76005+ 1721048117433.jpg-(526975 B)  おーいお前ら。質問なんだが、 |
| … | 114無題Name名無し 24/07/15(月)22:06:25No.76007そうだねx1swamponyxl+prodigyで顔だけ1024x1024で切り抜いた100枚ほどの画像を用意して、 |
| … | 115無題Name名無し 24/07/15(月)22:07:10No.76008+あと、全然関係ないんですけど、上でちょっと話題になってた話に関連して |
| … | 116無題Name名無し 24/07/15(月)22:09:02No.76009+コマンドラインから |
| … | 117無題Name名無し 24/07/16(火)00:21:33No.76041そうだねx1>No.76005 |
| … | 118無題Name名無し 24/07/16(火)01:17:13No.76055+>ちなForgeです。 |
| … | 119無題Name名無し 24/07/16(火)01:30:37No.76060+ 1721061037074.jpg-(350583 B)  >>No.76008 |
| … | 120無題Name名無し 24/07/16(火)01:31:31No.76061+2:おそらく辞典が一つだと、即座にプロンプトの文章であふれてしまうと思う。辞典にタイトルを付けられるようにして、目的に応じて、辞典を切り替えられるようにしてほしい。「Ponyエロ画像用」「PonyChibiキャラ漫才用」「兄魔人キャラ用」「兄魔人背景用」「Midjourney用」。といった塩梅だ。 |
| … | 121無題Name名無し 24/07/16(火)01:31:51No.76062+3:いままでプロンプトの文章の情報交換は、画像とか掲示板やホームページを通じて行っていたが、これができるようになれば自分のプロンプトの研究成果を、一括して他人に渡せるようになる。 |
| … | 122無題Name名無し 24/07/16(火)02:45:33No.76067+>No.76060 |
| … | 123無題Name名無し 24/07/16(火)04:03:12No.76076+ 1721070192653.png-(160049 B)  とりあえず初版。 |
| … | 124無題Name名無し 24/07/16(火)04:04:20No.76078+辞書機能は明日時間取れたら考えてみる。 |
| … | 125無題Name名無し 24/07/16(火)04:31:55No.76079+さっそくごめん、サジェスト機能がいつのまにか効かなくなってたので直しました |
| … | 126無題Name名無し 24/07/16(火)08:07:25No.76103+書き込みをした人によって削除されました |
| … | 127無題Name名無し 24/07/16(火)08:39:48No.76110+いろいろバグがあったのと、タグをドラッグ&ドロップできるようにした。続きはまた夜に。 |
| … | 128無題Name名無し 24/07/16(火)23:01:48No.76183+>>No.76110 |
| … | 129無題Name名無し 24/07/16(火)23:48:47No.76197+>>No.76055 |
| … | 130無題Name名無し 24/07/16(火)23:50:15No.76198+>続きはまた夜に |
| … | 131無題Name名無し 24/07/17(水)05:01:40No.76211+これEasy Prompt Selectorでよくね? |
| … | 132無題Name名無し 24/07/17(水)08:10:09No.76234+まあ確かに、拡張機能作ればいいじゃないとは思ったんだけど |
| … | 133無題Name名無し 24/07/17(水)08:14:44No.76235+>>No.76211 |
| … | 134無題Name名無し 24/07/17(水)10:58:34No.76250+こういうときに最初に検索するものは大事 |
| … | 135無題Name名無し 24/07/19(金)20:28:45No.76576+AIで動画作りたいんだけど、勉強するのにお勧めのサイト教えてくだされ。 |
| … | 136無題Name名無し 24/07/20(土)11:02:36No.76655+civitaiだけど、 |
| … | 137無題Name名無し 24/07/20(土)11:41:45No.76661+ 1721443305607.jpg-(23953 B)  Pixaiでこの画像の首に付いてるクロスのやつってプロンプト何で出るでしょうか? |
| … | 138無題Name名無し 24/07/20(土)13:37:57No.76675+ 1721450277032.png-(737957 B)  最近pony系列試しだしたけどなかなか難しい |
| … | 139無題Name名無し 24/07/20(土)14:49:22No.76688+>Pixaiでこの画像の首に付いてるクロスのやつってプロンプト何で出るでしょうか? |
| … | 140無題Name名無し 24/07/20(土)14:50:03No.76689そうだねx2>No.76675 |
| … | 141無題Name名無し 24/07/20(土)15:03:07No.76690+>No.76689 |
| … | 142無題Name名無し 24/07/20(土)20:26:56No.76731+ponyはXLのいいとこと悪いとこ両取りなのでネガティブプロンプトは一旦全消し |
| … | 143無題Name名無し 24/07/20(土)21:04:11No.76753+>出せるプロンプトはわからんが名称としてはスクールリボンとかクロスタイとかリボンタイって言うらしい |
| … | 144無題Name名無し 24/07/20(土)21:23:17No.76768+>No.76731 |
| … | 145無題Name名無し 24/07/20(土)21:56:46No.76790+ 1721480206620.png-(236440 B) 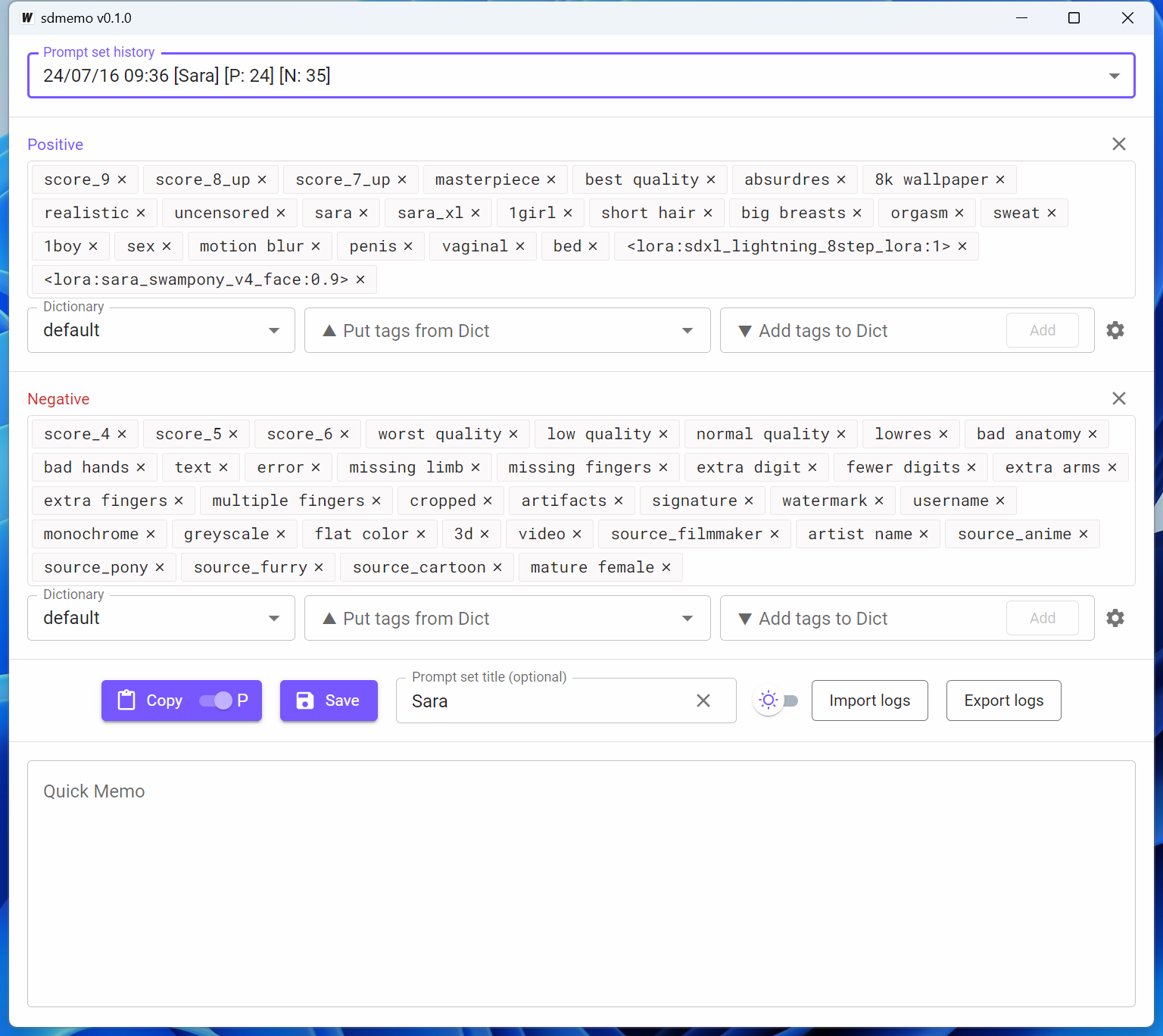 プロンプトメモアプリ、辞書機能つけたよ |
| … | 146無題Name名無し 24/07/20(土)22:52:52No.76821+>No.76790 |
| … | 147無題Name名無し 24/07/21(日)07:26:34No.76885そうだねx1>最近pony系列試しだしたけどなかなか難しい |
| … | 148無題Name名無し 24/07/21(日)07:29:09No.76886+>Pixaiでこの画像の首に付いてるクロスのやつってプロンプト何で出るでしょうか? |
| … | 149無題Name名無し 24/07/21(日)10:05:27No.76900+DynamicPromptでプロンプトのランダム生成してるんだけど |
| … | 150無題Name名無し 24/07/21(日)10:07:35No.76901+ 1721524055649.jpg-(28737 B)  civitaiでNEW順にしていましたが昨日の辺りから古い投稿が新作押しのけて |
| … | 151無題Name名無し 24/07/21(日)13:36:37No.76929+1.5のときもLoRA読み込むと1発目は少し時間がかかったけど |
| … | 152無題Name名無し 24/07/21(日)15:01:51No.76947+LORAをメモリに読み出してる時間だと思います。 |
| … | 153無題Name名無し 24/07/21(日)16:08:09No.76955+1.5のLoRAが144MBでXLは244MBなので読み込み速度ではないと思うんですよね |
| … | 154無題Name名無し 24/07/21(日)20:11:00No.77015そうだねx1 1721560260482.jpg-(4149886 B)  いろいろ教えてもらったおかげで、1回の出力でいい感じにバリエーションをだせるようになった |
| … | 155無題Name名無し 24/07/21(日)20:52:12No.77029+>No.76900 |
| … | 156無題Name名無し 24/07/21(日)20:57:10No.77031+>1.5のLoRAが144MBでXLは244MBなので読み込み速度ではないと思うんですよね |
| … | 157無題Name名無し 24/07/21(日)22:33:16No.77052+書き込みをした人によって削除されました |
| … | 158無題Name名無し 24/07/23(火)10:18:58No.77232+書き込みをした人によって削除されました |
| … | 159無題Name名無し 24/07/23(火)10:20:16No.77233+>それはこれも関係してる |
| … | 160無題Name名無し 24/07/23(火)10:28:21No.77235+>civitaiでNEW順にしていましたが昨日の辺りから古い投稿が新作押しのけて |
| … | 161無題Name名無し 24/07/23(火)10:48:04No.77236+>No.76900 |
| … | 162無題Name名無し 24/07/24(水)00:23:21No.77326そうだねx1SeaArtでオナニー画像作ってるのですが、 |
| … | 163無題Name名無し 24/07/24(水)07:04:16No.77367+出力した絵を出すの恥ずかしいのはわかるけどプロンプト部分出すのはそんなに恥ずかしくないと思うので |
| … | 164無題Name名無し 24/07/24(水)13:00:25No.77409+>出力した絵を出すの恥ずかしいのはわかるけどプロンプト部分出すのはそんなに恥ずかしくないと思うので |
| … | 165無題Name名無し 24/07/24(水)13:01:32No.77410+>>それはこれも関係してる |
| … | 166無題Name名無し 24/07/24(水)13:22:34No.77413+>civitaiでNEW順にしていましたが昨日の辺りから古い投稿が新作押しのけて |
| … | 167無題Name名無し 24/07/24(水)13:29:09No.77414そうだねx1>そのwikiリンク禁止だよ |
| … | 168無題Name名無し 24/07/24(水)13:38:28No.77416+>SeaArtでオナニー画像作ってるのですが、 |
| … | 169無題Name名無し 24/07/24(水)16:39:12No.77427そうだねx1Stable Diffusionたまに触ってるけど |
| … | 170無題Name名無し 24/07/24(水)16:58:00No.77430そうだねx3>No.77427 |
| … | 171無題Name名無し 24/07/24(水)17:47:42No.77437+書き込みをした人によって削除されました |
| … | 172無題Name名無し 24/07/24(水)18:56:10No.77445そうだねx2pnginfo見て全く真似てみるのが近道だと思う |
| … | 173無題Name名無し 24/07/24(水)19:03:38No.77448+deepnegative入れてたらネガティブプロンプト数が200超えてたのに気づかず変な絵しか出ないってなるなって設定いじくりまわしたりして虚無の時間を過ごしてしまった |
| … | 174無題Name名無し 24/07/24(水)22:05:44No.77487+書き込みをした人によって削除されました |
| … | 175無題Name名無し 24/07/24(水)22:15:09No.77489そうだねx2 1721826909335.png-(732644 B)  >SeaArtでオナニー画像作ってるのですが、 |
| … | 176無題Name名無し 24/07/25(木)12:06:22No.77565+forge入れた時ってzip解凍しただけだったと思うんだけど |
| … | 177無題Name名無し 24/07/25(木)12:09:16No.77566+>No.77430 |
| … | 178無題Name名無し 24/07/25(木)12:45:42No.77571そうだねx1>No.77565 |
| … | 179無題Name名無し 24/07/25(木)14:32:56No.77574+試行錯誤を繰り返すとついついプロンプトの要素数が増えたり |
| … | 180無題Name名無し 24/07/25(木)15:20:32No.77582+>完全新規インストールが無難よ |
| … | 181無題Name名無し 24/07/25(木)18:36:20No.77597+その程度の作業を面倒くさがるやつが必要なライブラリをチェックして適切に環境を準備できるとは思えない |
| … | 182無題Name名無し 24/07/25(木)18:55:46No.77599+新PCならgit入れてPython入れてのが面倒と思うな。 |
| … | 183無題Name名無し 24/07/25(木)18:58:04No.77602+ていうか「ちょっとだけ動かない(動かなかったので直したつもりだが、直すべきところを直せてない)」に絶対なるので、 |
| … | 184無題Name名無し 24/07/25(木)21:52:28No.77628+loraとかCheck Pointってフォルダにたくさん入れてると生成遅くなる? |
| … | 185無題Name名無し 24/07/25(木)22:13:09No.77637+ならないんじゃないかな |
| … | 186無題Name名無し 24/07/26(金)21:07:38No.77749+>No.77628 |
| … | 187無題Name名無し 24/07/27(土)23:31:20No.77913+>1.5のときもLoRA読み込むと1発目は少し時間がかかったけど |
| … | 188無題Name名無し 24/07/28(日)05:03:31No.77930+ 1722110611314.png-(144352 B)  こういう感じの、ローポリゴンの辺がネオンカラーの線みたいになってるのってなんと書き表したらいいのでしょうか |
| … | 189無題Name名無し 24/07/28(日)08:10:17No.77941+ニッチっぽい表現に共通する探し方として、そう言う表現がジャンル化するほど定着してるなら |
| … | 190無題Name名無し 24/07/28(日)11:01:36No.77954そうだねx2>こういう感じの、ローポリゴンの辺がネオンカラーの線みたいになってるのってなんと書き表したらいいのでしょうか |
| … | 191無題Name名無し 24/07/28(日)11:04:18No.77955+ 1722132258886.png-(1262651 B)  ちなみに段ボール呪文は以下で |
| … | 192無題Name名無し 24/07/28(日)12:28:25No.77962+言葉で表現するとしたらなんだろ |
| … | 193無題Name名無し 24/07/28(日)13:26:56No.77966+ 1722140816434.jpg-(153379 B)  Bingに要素を聞いて描いてもらった |
| … | 194無題Name名無し 24/07/28(日)15:44:51No.77976+>Bingに要素を聞いて描いてもらった |
| … | 195無題Name名無し 24/07/28(日)16:06:34No.77979+書き込みをした人によって削除されました |
| … | 196無題Name名無し 24/07/28(日)16:07:02No.77980そうだねx1webuiでcolabで動かしているけど |
| … | 197無題Name名無し 24/07/28(日)17:02:31No.77995そうだねx2 1722153751539.jpg-(191498 B)  >No.77930 |
| … | 198無題Name77930 24/07/28(日)17:06:23No.77996そうだねx3 1722153983347.jpg-(113596 B)  別のもこんな感じ |
| … | 199無題Name名無し 24/07/29(月)15:32:28No.78122+ 1722234748156.png-(47429 B)  xormersでエラー出てこの辺りに書いてあるっぽいんですけど |
| … | 200無題Name名無し 24/07/29(月)15:34:16No.78123+--reinstall-xformers では解決しませんでした |
| … | 201無題Name名無し 24/07/29(月)16:05:21No.78125+Pythonのページ見てたらxFormers不要って書いてた…別に要らなかったのかこれ |
| … | 202無題Name名無し 24/07/31(水)06:40:40No.78313そうだねx111年以上ぶりくらいにまたローカル生成触りだしたんだけど |
| … | 203無題Name名無し 24/07/31(水)07:18:59No.78317+たしかにローカルの主流はSDXLやponyに移ったけど |
| … | 204無題Name名無し 24/07/31(水)07:23:39No.78319+旧Forge(v1.8.0ベース)を利用するとVRAMの節約に役立つよ |
| … | 205無題Name名無し 24/07/31(水)13:04:48No.78340そうだねx1>今はもうSDXLやらponyってのが主流で以前のSD1.5とかは |
| … | 206無題Name名無し 24/07/31(水)13:07:11No.78341+まあ逆に言えば好みの絵が出せればXLのほうが使い勝手が良いのも事実で |
| … | 207無題Name名無し 24/07/31(水)14:31:37No.78346+特定のLoRAがSD1.5製のはあるけど |
| … | 208無題Name名無し 24/08/01(木)16:53:58No.78469そうだねx20>それとSDXLやponyではLCM・Lightning・Hyperなどの省ステップ技術を使うと |
| … | 209無題Name名無し 24/08/01(木)18:27:53No.78481そうだねx1「本物」とかいうけど |
| … | 210無題Name名無し 24/08/01(木)18:56:19No.78483+書き込みをした人によって削除されました |
| … | 211無題Name名無し 24/08/01(木)22:07:52No.78498+今までForgeでPony触っててワイルドカード試してみたいんだけどオススメある?ComfyUIのワイルドカードは選択肢が多すぎて分からん |
| … | 212無題Name名無し 24/08/02(金)07:32:31No.78553そうだねx40そもそもTurboやLightingの目的は処理時間の速い生成であって処理負荷の軽い生成じゃねえ |
| … | 213無題Name名無し 24/08/02(金)13:22:03No.78586そうだねx1>今はもうSDXLやらponyってのが主流で以前のSD1.5とかは |
| … | 214無題Name名無し 24/08/02(金)13:29:37No.78588+Automatic1111でシンプルに画像だけをt2iからi2iに転送する拡張機能とかないかな? |
| … | 215無題Name名無し 24/08/02(金)18:58:35No.78618+ 1722592715121.png-(42258 B)  >webuiでcolabで動かしているけど |
| … | 216無題Name名無し 24/08/04(日)10:49:34No.78865+ 1722736174146.png-(502965 B)  下半身に着てるのなんていう服? |
| … | 217無題Name名無し 24/08/04(日)13:31:29No.78880そうだねx2 1722745889952.jpg-(125646 B)  日本だとサロペットスカートというらしいが |
| … | 218無題Name名無し 24/08/04(日)15:11:02No.78888そうだねx1ダンボールタグ的にはこっちのような気がする |
| … | 219無題Name名無し 24/08/04(日)15:39:42No.78890+なるほど ありがとう |
| … | 220無題Name名無し 24/08/04(日)19:58:32No.78917+書き込みをした人によって削除されました |
| … | 221無題Name名無し 24/08/05(月)14:34:08No.78993+stable diffusion 1.10.1だとimg2imgの中にupscaler無いんだね |
| … | 222無題Name名無し 24/08/05(月)19:13:17No.79019+>stable diffusion 1.10.1だとimg2imgの中にupscaler無いんだね |
| … | 223無題Name名無し 24/08/05(月)19:18:39No.79021+ちなみにtxt2imgやimg2imgのUIの上下の順番を並び替えたい時は |
| … | 224無題Name名無し 24/08/05(月)20:00:17No.79031+うわああ出たああ |
| … | 225無題Name名無し 24/08/06(火)20:33:07No.79136+ponyXL-V6学習のキャプション付けについて質問します |
| … | 226無題Name名無し 24/08/06(火)21:51:47No.79139+超初心者ですみません |
| … | 227無題Name名無し 24/08/12(月)20:16:31No.79830+>もしかして学習時はスコアタグとソースタグ必要ないですか? |
| … | 228無題Name名無し 24/08/13(火)16:15:06No.79909+画質面に関する特別な注釈が必要な場合じゃなけりゃ要らないと思う |
| … | 229無題Name名無し 24/08/15(木)16:01:28No.80102+ 1723705288752.jpg-(265577 B)  こう言う透明感ある髪を出すのってどうやればいいんだろう?薄い色とか複数の色を重ねてグラデーション作って欲しいのよね(これはAI絵じゃないけど) |
| … | 230無題Name名無し 24/08/15(木)20:45:15No.80137+ケツ中のcross-sectionをしようとすると別の穴の中になってしまいます |
| … | 231無題Name名無し 24/08/17(土)10:22:04No.80356+バッチ処理(i2iとかcontrol net)にフォルダを読ませた場合 |
| … | 232無題Name名無し 24/08/17(土)22:18:42No.80447+>No.80102 |
| … | 233無題Name名無し 24/08/18(日)17:24:55No.80618+ 1723969495965.jpg-(66497 B)  よくある質問なので適当にフローチャートを作った |
| … | 234無題Name名無し 24/08/19(月)01:08:09No.80686+ちょっと手こずってるからジャブで聞いときたいんだけど以下のスペックって1111webuiローカルのSDXLで1024*1024一枚出すのに不足してる? |
| … | 235無題Name名無し 24/08/19(月)01:09:25No.80688+あ違う違う |
| … | 236無題Name名無し 24/08/19(月)06:44:45No.80705+>No.80686 |
| … | 237無題Name名無し 24/08/19(月)19:18:22No.80769+ 1724062702773.png-(157096 B)  ありがとうございます。…改めて相談していいですか? |
| … | 238無題Name名無し 24/08/19(月)21:32:39No.80781+>No.80769 |
| … | 239無題Name名無し 24/08/19(月)21:41:52No.80784+ものすごいくだらない質問で恐縮なんだけど |
| … | 240無題Name名無し 24/08/19(月)22:14:15No.80786+ 1724073255025.jpg-(282029 B) 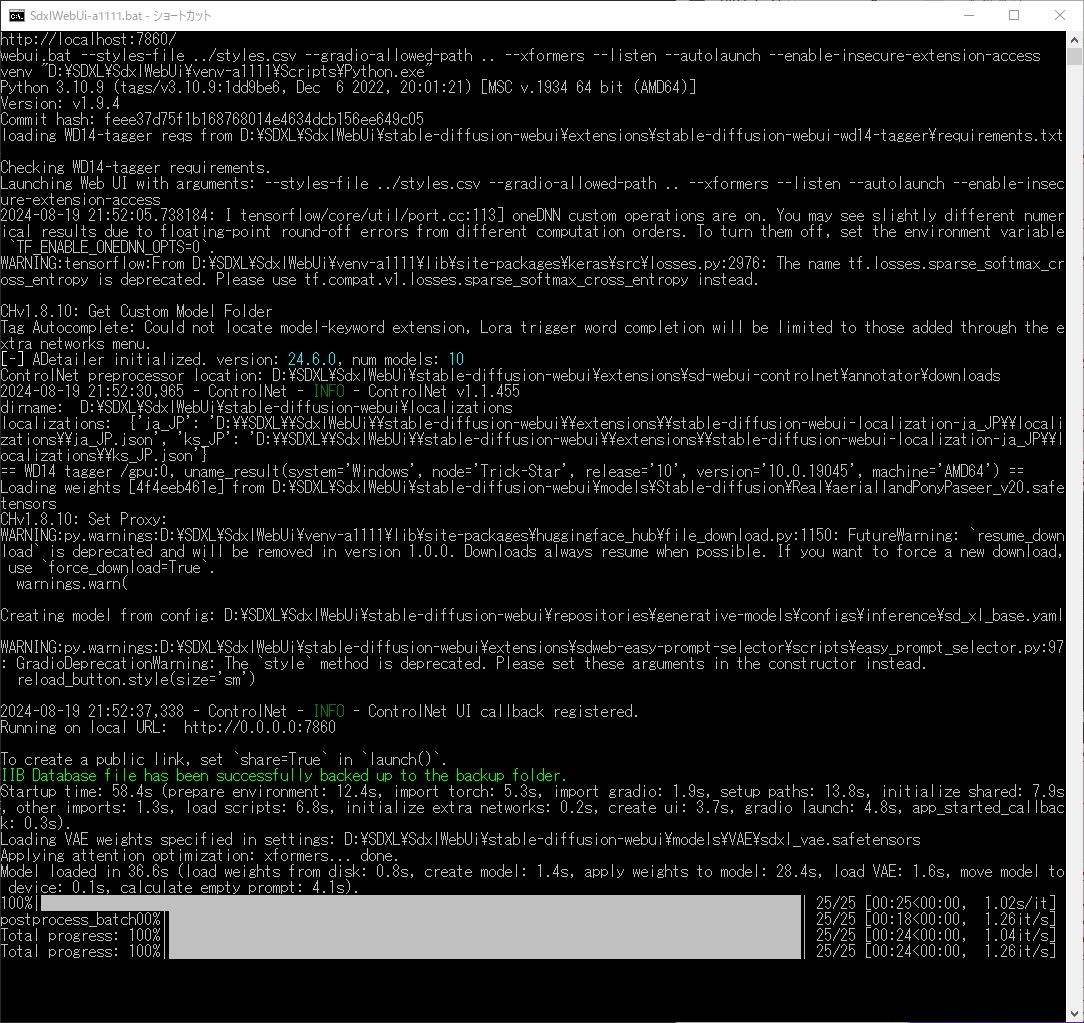 >>No.80769 |
| … | 241無題Name名無し 24/08/19(月)22:39:33No.80791+>No.80769 |
| … | 242無題Name名無し 24/08/19(月)22:44:52No.80792+>No.80769 |
| … | 243無題Name名無し 24/08/19(月)22:45:35No.80793+最後切れた |
| … | 244無題Name名無し 24/08/19(月)23:32:12No.80807+ 1724077932321.png-(30123 B)  >No.80769 です。色々ご助言いただけて感謝です。 |
| … | 245無題Name名無し 24/08/20(火)00:21:54No.80814+>使ってるモデルは現在配布されて居ないと思うので、消さないほうが良いです。 |
| … | 246無題Name名無し 24/08/20(火)07:11:46No.80850+しびたいで消えててもHuggingFaceにはあるとかよくある |
| … | 247無題Name名無し 24/08/20(火)18:16:22No.80893+No.80769 です。対処結果報告の前にエラーに関する追加の情報です。言葉の洪水をわっと浴びせるのも忍びなくて言いそびれてました。 |
| … | 248無題Name名無し 24/08/20(火)18:17:42No.80894+症状として全般的にGPU?RAM?の限界を超えたような振る舞いを見せます。4回に1回ほどブラウザの描画がおかしくなったり画面が異常にズームされたり。10回に1回くらいWindowsポップアップで"メモリはreadになることはできませんでした"というメッセージが出てきたりもします。 |
| … | 249無題Name名無し 24/08/20(火)18:18:55No.80895+やってみたことと回答 |
| … | 250無題Name名無し 24/08/20(火)18:22:27No.80896+ 1724145747335.png-(466339 B)  特定の対処の結果 |
| … | 251無題Name名無し 24/08/20(火)18:25:55No.80897+>モデルとかVAEを疑ってみるとか。 |
| … | 252無題Name名無し 24/08/20(火)18:26:52No.80898+実際にタスクマネージャーでメモリの方を注視してみたら生成中のRAM使用量が限界を迎えてます… |
| … | 253無題Name名無し 24/08/20(火)18:30:30No.80900+まとめるとどうもRAMが足りていなくてStable diffusion(というかpython?)が停止しているっぽいです? |
| … | 254無題Name名無し 24/08/20(火)18:55:21No.80902+たくさん書き込んで早々やや気まずいんですがイベントビューアを見たらまさしく生成のタイミングでメモリ不足の警告が出ました… |
| … | 255無題Name名無し 24/08/20(火)20:28:51No.80919+>No.80902 |
| … | 256無題Name名無し 24/08/20(火)21:15:43No.80930+ 1724156143912.png-(1847475 B)  >起動引数 |
| … | 257無題Name名無し 24/08/20(火)21:43:39No.80937+ 1724157819407.png-(566647 B)  スペックです |
| … | 258無題Name名無し 24/08/20(火)21:56:33No.80938+ちなみにコマンドコンソールで |
| … | 259無題Name名無し 24/08/20(火)22:06:14No.80941+>ちなみにコマンドコンソールで |
| … | 260無題Name名無し 24/08/20(火)22:08:46No.80942+(調べる) |
| … | 261無題Name名無し 24/08/20(火)23:11:47No.80946+画像生成後にhires.fixは動くので、その設定がメモリ食いすぎだとか。 |
| … | 262無題Name名無し 24/08/20(火)23:19:38No.80948+エラーを見た感じtorchとCUDAに問題ありそうな気配だけど |
| … | 263無題Name名無し 24/08/21(水)01:33:15No.80958+ 1724171595945.png-(166963 B)  No.80769 です。 |
| … | 264無題Name名無し 24/08/21(水)02:11:25No.80961+python3.10.6に合うtorchは1.11とか1.12だったと思う |
| … | 265無題Name名無し 24/08/21(水)06:32:57No.80973+環境構築のハウツーなんかググればいくらでも出てくるから |
| … | 266無題Name名無し 24/08/21(水)12:45:31No.81003+書き込みをした人によって削除されました |
| … | 267無題Name名無し 24/08/21(水)17:21:38No.81021+No.80769 です。 |
| … | 268無題Name名無し 24/08/21(水)17:21:59No.81022+ここに助けを求めた最大の理由は問題解決が行き詰まっていたからでした。 |
| … | 269無題Name名無し 24/08/21(水)18:25:57No.81031+・WebUI付属の初期スクリプトを起動するためだけの、windowsインストーラで入れるpython3.10.6(要pip) |
| … | 270無題Name名無し 24/08/21(水)19:37:42No.81036+StableDifusionの場合torchとかのインストールは |
| … | 271無題Name名無し 24/08/21(水)20:32:23No.81044そうだねx2 1724239943219.png-(1519707 B)  >No.80769 |
| … | 272無題Name名無し 24/08/21(水)20:37:54No.81045そうだねx1テンション上がりすぎて文章推敲で消すはずだった変なコマンド混じっちゃってるけど気にしないでください… |
| … | 273無題Name名無し 24/08/21(水)21:44:02No.81054+https://www.pixiv.net/users/34313911 |
| … | 274無題Name名無し 24/08/21(水)22:33:57No.81065そうだねx1>No.81044 |
| … | 275無題Name名無し 24/08/22(木)03:23:15No.81107+教師画像の不要な小物を加工で消して学習させているんですが、物を手に持っている絵の物や食事してる絵の食べ物を消しても、生成した絵が物をエアーで物を持ったり食べ物食べてるっぽいポーズをしてしまいます。どうすれば変なポーズになりませんか? |
| … | 276無題Name名無し 24/08/22(木)04:34:29No.81111+>No.81107 |
| … | 277無題Name名無し 24/08/22(木)05:35:24No.81115+>No.81111 |
| … | 278無題Name名無し 24/08/22(木)07:15:15No.81122そうだねx2ボランタリベースの質問スペースでは「解決したか」「解決しなかったなら何が起こったのか」の情報自体が報酬なので、やってから結果を報告するのがいいよ |
| … | 279無題Name名無し 24/08/22(木)08:05:12No.81127+書き込みをした人によって削除されました |
| … | 280無題Name名無し 24/08/22(木)20:24:26No.81191そうだねx4質問した後「自己解決しました」で去られるのが一番モヤモヤする |
| … | 281無題Name名無し 24/08/22(木)21:01:19No.81196+これってどういうLoRAなんですか? |
| … | 282無題Name名無し 24/08/22(木)21:55:46No.81202+>No.81196 |
| … | 283無題Name名無し 24/08/22(木)22:25:17No.81208+教師画像の質問した者です。 |
| … | 284無題Name名無し 24/08/22(木)23:24:35No.81221+>No.81208 |
| … | 285無題Name名無し 24/08/22(木)23:41:48No.81225+>No.81202 |
| … | 286無題Name名無し 24/08/23(金)17:24:14No.81277+Adetailer用のモデルもSDXLならSDXL用のものを使わなきゃいけないのかな |
| … | 287無題Name名無し 24/08/27(火)09:21:51No.81819+AI関係の画像スレ立てしてビンガーさんが来るとめっちゃくちゃテンション下がって |
| … | 288無題Name名無し 24/08/27(火)15:18:31No.81842+聞いてもないのに「bingだとこれが限界」とか言って正方形のイマイチ画像出してくる人だな |
| … | 289無題Name名無し 24/08/28(水)21:14:28No.82009+書き込みをした人によって削除されました |
| … | 290無題Name名無し 24/08/29(木)17:51:18No.82113+既出でしたら申し訳ないんですがlora作成時のタグ付について質問させてください。現在dataset tag editorでタグ付をしているのですが、例えばあるキャラの同じ衣装のバストアップ画像と全身画像をそれぞれエディターにかけるとバストアップ画像には胸元のred ribbonがタグで出るけど全身画像では出てこないという状況が発生します。この場合全身画像の方にも手動でred ribbonとタグを追加したほうが良いんでしょうか? |
| … | 291無題Name名無し 24/08/29(木)19:30:01No.82128+>No.81819 |
| … | 292無題Name名無し 24/08/30(金)00:10:49No.82162+>No.82113 |
| … | 293無題Name名無し 24/08/30(金)11:28:39No.82206+stable diffusionでプロンプト増加により絵柄が変わる症状について |
| … | 294無題Name名無し 24/08/30(金)16:33:50No.82222+>No.82162 |
| … | 295無題Name名無し 24/09/01(日)08:08:29No.82443+>No.82206 |
| … | 296無題Name名無し 24/09/01(日)13:54:41No.82468+魔人系で個性的なモデルあったら教えて |
| … | 297無題Name名無し 24/09/01(日)15:10:11No.82483+>ちょっと手こずってるからジャブで聞いときたいんだけど以下のスペックって1111webuiローカルのSDXLで1024*1024一枚出すのに不足してる? |
| … | 298無題Name名無し 24/09/01(日)19:35:53No.82500+うちはメインメモリ32GBでXL1枚20分くらい!(聞いてねえ) |
| … | 299無題Name名無し 24/09/02(月)23:12:41No.82666+コラージュにも使えるもんなんかね |
| … | 300無題Name名無し 24/09/03(火)03:26:35No.82690+できるけど、生成結果が「ランダム」なので忍耐が必要 |
| … | 301無題Name名無し 24/09/03(火)10:01:40No.82726+StabilityMatrixのForge使ってるんだけど |
| … | 302無題Name名無し 24/09/03(火)13:10:00No.82732+>できるけど、生成結果が「ランダム」なので忍耐が必要 |
| … | 303無題Name名無し 24/09/03(火)21:04:05No.82764+ 1725365045878.png-(1467151 B)  指の修正どうしてますか? |
| … | 304無題Name名無し 24/09/04(水)04:54:17No.82815+昔のスレで手のdepthと手のopenposeを併用するというのがあった |
| … | 305無題Name名無し 24/09/04(水)08:45:10No.82828+手の修正はガチャ |
| … | 306無題Name名無し 24/09/04(水)12:04:44No.82839+レタッチって別のソフトってこと?クリスタあるからこれで頑張るしかないか |
| … | 307無題Name名無し 24/09/04(水)13:48:11No.82843+最近昨今、手以外が結構なんとかなってるので |
| … | 308無題Name名無し 24/09/04(水)14:34:25No.82847+pony系は結構良くなってるけど |
| … | 309無題Name名無し 24/09/04(水)14:45:13No.82851そうだねx1 1725428713066.jpg-(211423 B)  >レタッチって別のソフトってこと?クリスタあるからこれで頑張るしかないか |
| … | 310無題Name名無し 24/09/04(水)14:46:05No.82854そうだねx1 1725428765880.jpg-(160405 B)  手のとこだけインペイントで軽くなじませる |
| … | 311無題Name名無し 24/09/05(木)04:49:13No.82958+>No.82851 |
| … | 312無題Name名無し 24/09/05(木)05:35:56No.82961+ 1725482156305.png-(310061 B) 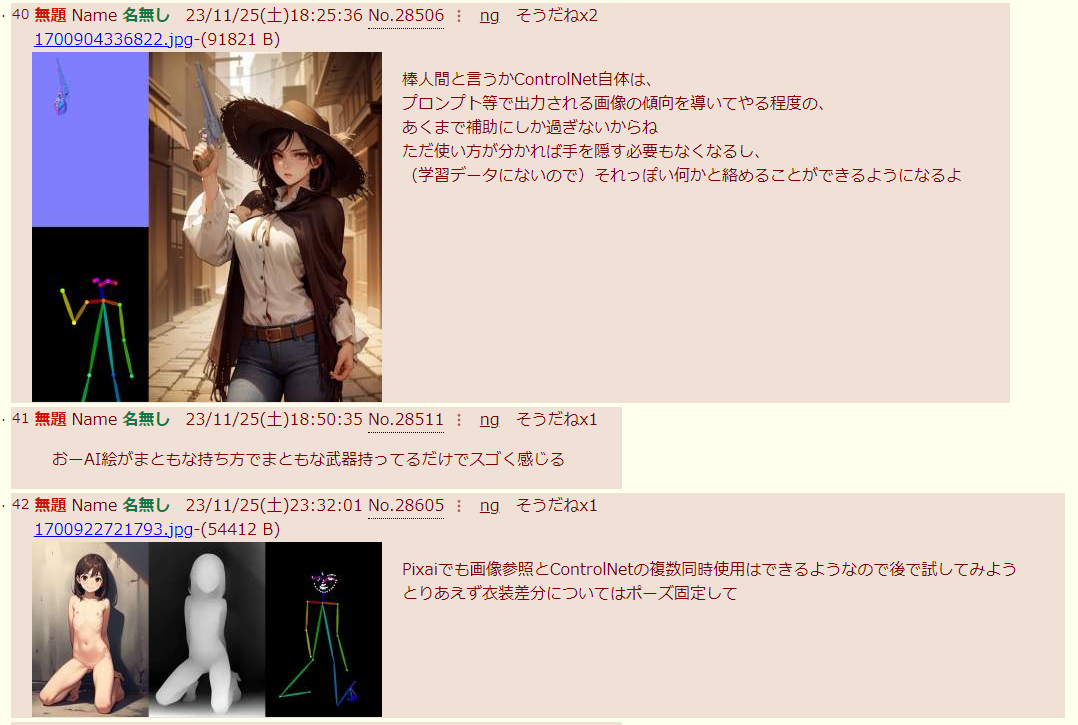 指と銃器はnormal mapがいいぞ! |
| … | 313無題Name名無し 24/09/05(木)09:54:38No.82981+昨日NovelAIのanlasがいつの間にか1万残から5000ほど減ってたんだけど何でだろう |
| … | 314無題Name名無し 24/09/05(木)10:42:59No.82983+たぶんわかる人はいないと思いつつ |
| … | 315無題Name名無し 24/09/05(木)11:06:46No.82986+>No.82443 |
| … | 316無題Name名無し 24/09/05(木)15:23:40No.82997+>No.82206 |
| … | 317無題Name名無し 24/09/05(木)18:42:41No.83018+>プロンプトが増えていくとどうしても絵柄が変わってしまいがちで困ってます |
| … | 318無題Name名無し 24/09/05(木)19:44:09No.83024+ 1725533049770.jpg-(239632 B)  >指の修正どうしてますか? |
| … | 319無題Name名無し 24/09/06(金)02:44:18No.83092+オホ声とか喘ぎ声とか付けたい時ってみんなどこの素材使ってる? |
| … | 320無題Name名無し 24/09/06(金)05:35:03No.83103+>>指の修正どうしてますか? |
| … | 321無題Name名無し 24/09/06(金)06:51:00No.83110+ 1725573060663.png-(806450 B)  mayのSOZAIスレでもらった奴とか上書きしてる |
| … | 322無題Name名無し 24/09/06(金)10:21:56No.83137そうだねx4 1725585716419.jpg-(205302 B)  SOZAIおかり |
| … | 323無題Name名無し 24/09/06(金)12:24:03No.83148+>SOZAIおかり |
| … | 324無題Name名無し 24/09/06(金)23:23:42No.83205+PiXAIのLoRA学習がTopページからなくなってるけどどっから入ったらいいんだろう |
| … | 325無題Name名無し 24/09/07(土)01:01:36No.83215そうだねx1トップページ左あるモデルという項目から飛ぶと |
| … | 326無題Name名無し 24/09/07(土)09:33:28No.83257+ありがととし |
| … | 327無題Name名無し 24/09/07(土)14:41:52No.83286+>StabilityMatrixのForge使ってるんだけど |
| … | 328無題Name名無し 24/09/07(土)15:03:26No.83290+書き込みをした人によって削除されました |
| … | 329無題Name名無し 24/09/07(土)15:04:57No.83291+書き込みをした人によって削除されました |
| … | 330無題Name名無し 24/09/07(土)15:05:27No.83292+ 1725689127426.png-(3835026 B)  3Dモデルを入力して構図・ポーズ・服装・表情とかを保持したままイラスト化したいのですがなにかいい方法ないでしょうか |
| … | 331無題Name名無し 24/09/07(土)15:05:53No.83293+ 1725689153063.png-(5667696 B)  比較的うまくいった例 |
| … | 332無題Name名無し 24/09/07(土)21:22:11No.83328+>No.83286 |