 無題Name名無し25/05/17(土)13:33:23No.120078そうだねx9
18日20:12頃消えます
無題Name名無し25/05/17(土)13:33:23No.120078そうだねx9
18日20:12頃消えます
AI関連のニューススレこのスレは古いので、もうすぐ消えます。
立ってないようなので
削除された記事が14件あります.見る
| … | 1無題Name名無し 25/05/17(土)13:36:37No.120081そうだねx1Google DeepMindからAlphaEvolveが発表 |
| … | 2無題Name名無し 25/05/17(土)13:39:26No.120086そうだねx1WindsurfからSWE-1モデルファミリがリリース |
| … | 3無題Name名無し 25/05/17(土)13:43:39No.120090そうだねx1OpenAIからCodexが発表 |
| … | 4無題Name名無し 25/05/17(土)18:45:02No.120157そうだねx1 1747475102727.jpg-(186184 B) 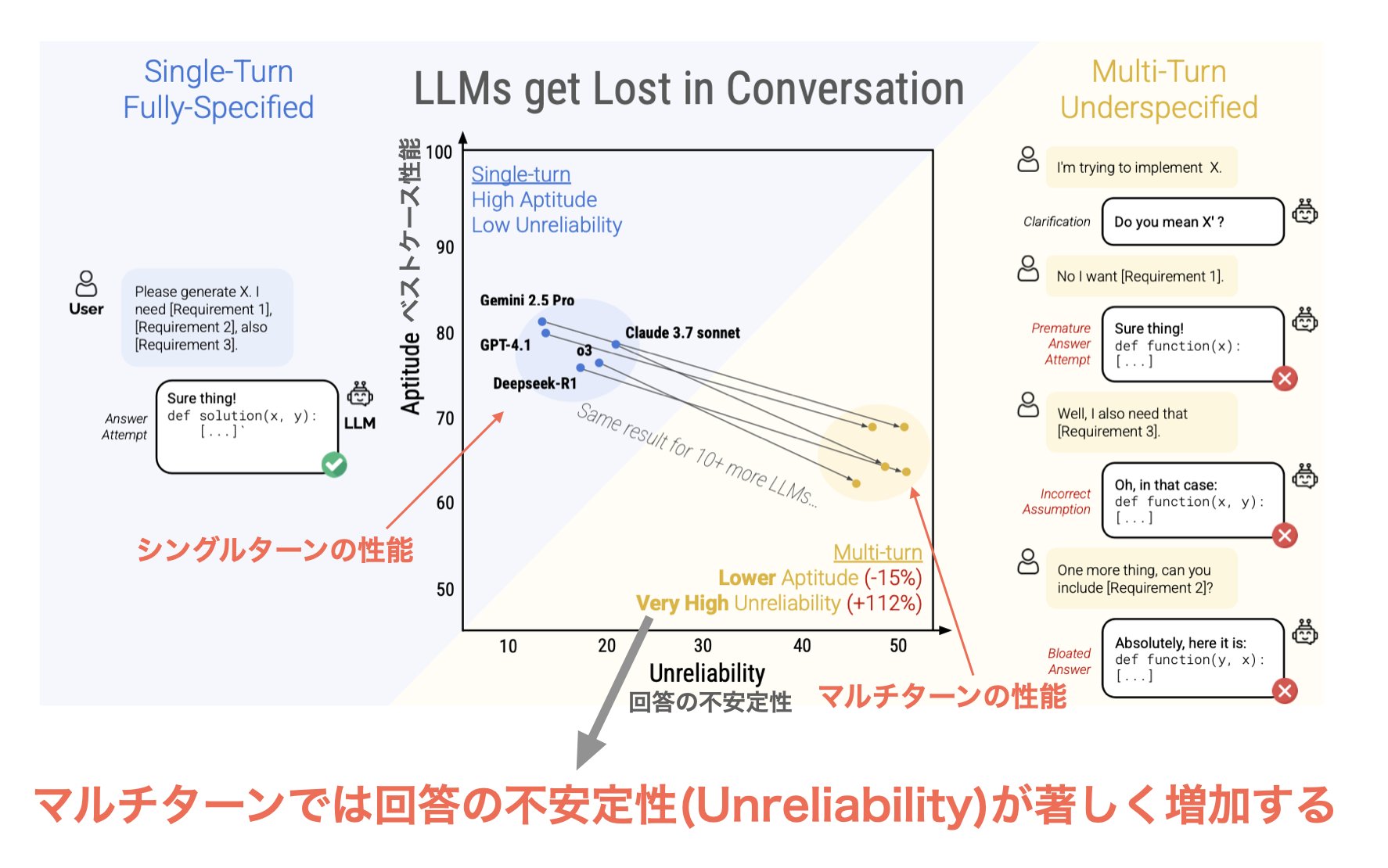 シングルターンとマルチターンによる6つの生成タスク (コード、数学、SQL、API 呼び出し、データからテキストへの変換、ドキュメントの要約) にわたって、15 のトップ LLM (GPT-4.1、Gemini 2.5 Pro、Claude 3.7 Sonnet、Deepseek-R1 など) による大規模なシミュレーションを実施しました。 |
| … | 5無題Name名無し 25/05/17(土)18:50:07No.120160+>No.120157 |
| … | 6無題Name名無し 25/05/19(月)19:24:14No.120419そうだねx1会話中、相手の“ウソ”をこっそり教えてくれるスマートウォッチ AIが瞬時にファクトチェック |
| … | 7無題Name名無し 25/05/19(月)21:05:01No.120441+スレッドを立てた人によって削除されました |
| … | 8無題Name名無し 25/05/20(火)09:49:38No.120493そうだねx2#NVIDIA、RTX GPUでのAI推論より簡単に高速化できる「TensorRT for RTX」 |
| … | 9無題Name名無し 25/05/20(火)11:17:36No.120499そうだねx1Microsoft Build 2025 |
| … | 10無題Name名無し 25/05/21(水)07:28:12No.120600そうだねx1Google I/O 2025 |
| … | 11Xで話題騒然「Gemini Diffusion」Name名無し 25/05/22(木)02:31:22No.120703+ 1747848682471.mp4-(272505 B)  >Googleは、画像生成AIなどで使われている「拡散モデル」の技術を使って作成されたAIモデル「Gemini Diffusion」を発表しました。 |
| … | 12無題Name名無し 25/05/22(木)08:33:49No.120728そうだねx2OpenAIとデザイン企業ioの合併 |
| … | 13無題Name名無し 25/05/22(木)11:26:08No.120734そうだねx2MistralからDevstralがリリース |
| … | 14無題Name名無し 25/05/22(木)19:22:36No.120773そうだねx1PLaMoからPLaMo 2.0 Primeがリリース |
| … | 15無題Name名無し 25/05/23(金)05:26:17No.120822そうだねx2Claude4がリリース |
| … | 16無題Name名無し 25/05/25(日)22:40:57No.121233そうだねx3>Veo3では音声付のビデオ生成も可能に |
| … | 17無題Name名無し 25/05/26(月)16:09:34No.121300+書き込みをした人によって削除されました |
| … | 18無題Name名無し 25/05/29(木)23:48:18No.121651そうだねx1DeepSeek-R1-0528がリリース |
| … | 19無題Name名無し 25/06/01(日)18:36:16No.122174そうだねx2https://x.com/jiwasawa/status/1928268298866594292 |
| … | 20無題Name名無し 25/06/04(水)13:47:33No.122654そうだねx3Builder.ai破綻の真相:700人のインドエンジニアが「AI」を偽装、Microsoft出資の4億4500万ドル調達企業が破産 |
| … | 21無題Name名無し 25/06/07(土)16:27:05No.123080そうだねx1現在 seaartでプロンプト欄にnipple vagina などのセンシティブなワードがキーワード検閲されている模様 |
| … | 22無題Name名無し 25/06/07(土)19:57:56No.123116そうだねx1>No.123080 |
| … | 23無題Name名無し 25/06/08(日)15:23:42No.123259そうだねx2Dual-Process Image Generation: |
| … | 24無題Name名無し 25/06/08(日)15:52:37No.123261そうだねx1FreeTimeGS: |
| … | 25無題Name名無し 25/06/08(日)16:27:58No.123264そうだねx2 1749367678541.jpg-(157962 B) 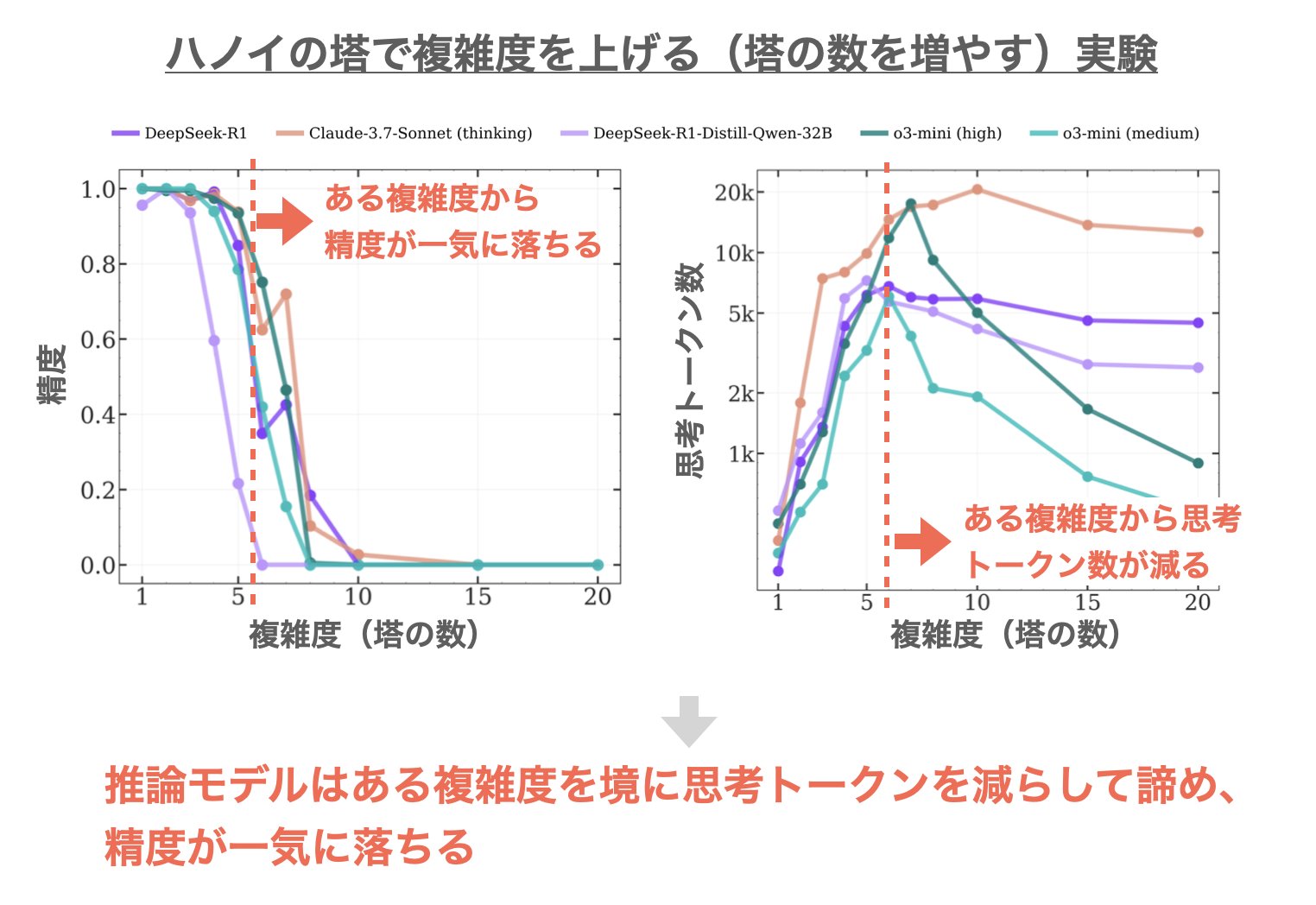 Appleの研究により、推論モデル(LRM)は問題が一定以上に複雑になると、思考放棄して一気に精度が落ちることが判明した。 |
| … | 26無題Name名無し 25/06/09(月)17:29:46No.123474そうだねx1>FreeTimeGS: |
| … | 27無題Name名無し 25/06/09(月)20:00:35No.123490そうだねx1 1749466835486.jpg-(249105 B) 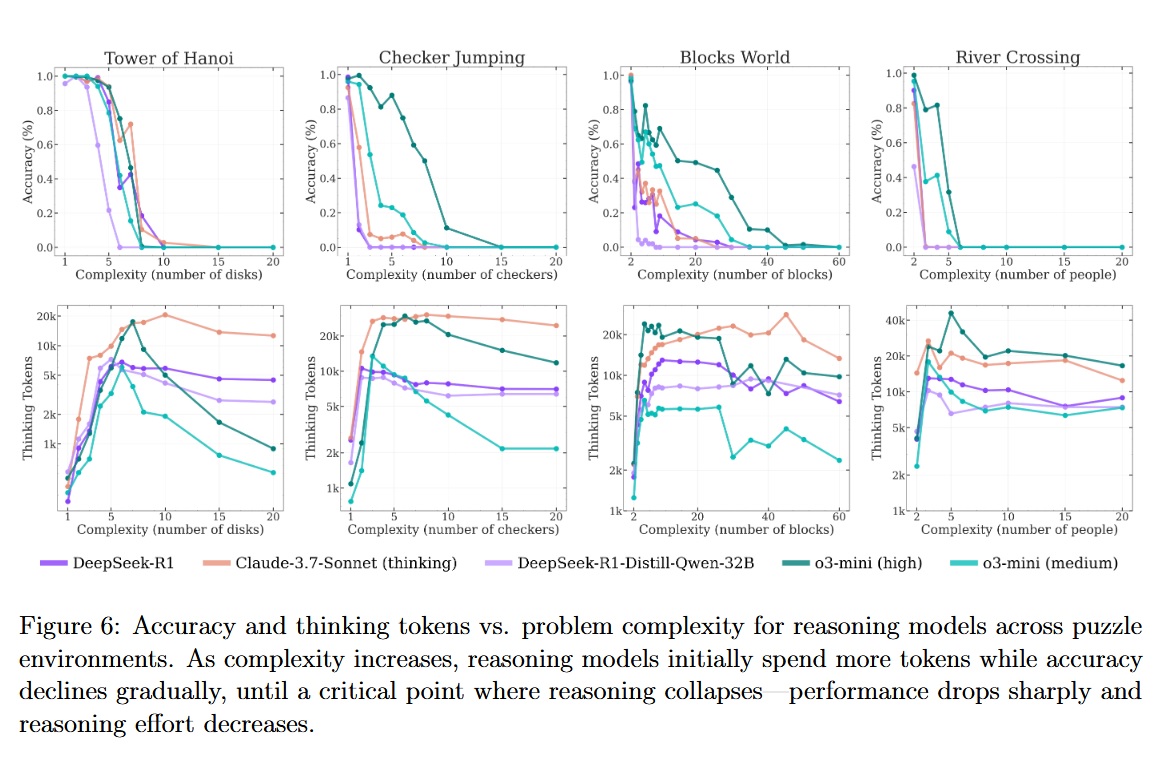 >Appleの研究により、推論モデル(LRM)は問題が一定以上に複雑になると、思考放棄して一気に精度が落ちることが判明した。 |
| … | 28無題Name名無し 25/06/11(水)00:01:29No.123750そうだねx1Mistralから初の推論モデルMagistral |
| … | 29無題Name名無し 25/06/11(水)06:28:01No.123776+OpenAIからo3-proがリリース |
| … | 30無題Name名無し 25/06/11(水)10:06:41No.123799+スレッドを立てた人によって削除されました |
| … | 31無題Name名無し 25/06/11(水)16:35:42No.123826+「生成AIで作成」女の子の裸の画像を共有疑い 50代の男を逮捕 愛知県警で初、わいせつ電磁的記録媒体陳列容疑で検挙 - YAHOO! ニュース |
| … | 32無題Name名無し 25/06/12(木)14:57:58No.123966そうだねx1Text-to-LoRA(T2L): |
| … | 33無題Name名無し 25/06/12(木)16:11:43No.123971+米ディズニーなど “生成AI 作成画像が著作権を侵害”と提訴 - NHK |
| … | 34無題Name名無し 25/06/12(木)19:10:23No.123986+Seaweed APT2 |
| … | 35無題Name名無し 25/06/13(金)00:19:02No.124048そうだねx1”AI彼女”Z世代ユーザーの80%が「合法ならAIと結婚したい」と回答 - ナゾロジー |
| … | 36無題Name名無し 25/06/13(金)18:14:31No.124175+Apple Vision Proの次期OSであるvisionOS 26に”Spatial Scene”を搭載予定 |
| … | 37無題Name名無し 25/06/13(金)18:27:53No.124177+視覚言語モデル(Vision Language Models)についてのオライリー書籍の10日間フリートライアルが実施(英語) |
| … | 38無題Name名無し 25/06/13(金)19:19:53No.124184+評価認識: |
| … | 39無題Name名無し 25/06/14(土)21:05:16No.124435そうだねx1特許庁、AI生成物「商標」容認 現行制度で出願・登録 - 日刊工業新聞 |
| … | 40無題Name名無し 25/06/15(日)23:41:57No.124653+ 1749998517007.jpg-(731942 B) 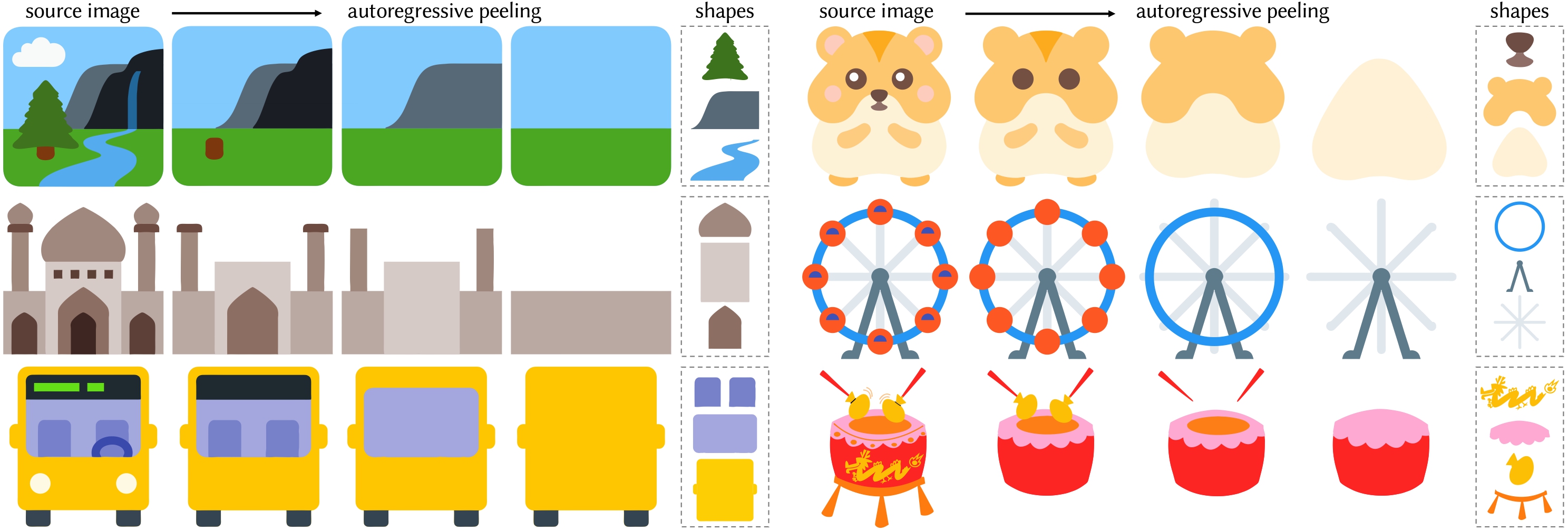 LayerPeeler: |
| … | 41無題Name名無し 25/06/16(月)00:47:50No.124660+Microsoftの「Copilot 3D」 |
| … | 42無題Name名無し 25/06/16(月)01:39:40No.124667そうだねx1 1750005580335.gif-(30535 B)  Breathing Life Into Sketches Using |
| … | 43無題Name名無し 25/06/16(月)01:49:57No.124669そうだねx1 1750006197021.png-(863517 B) 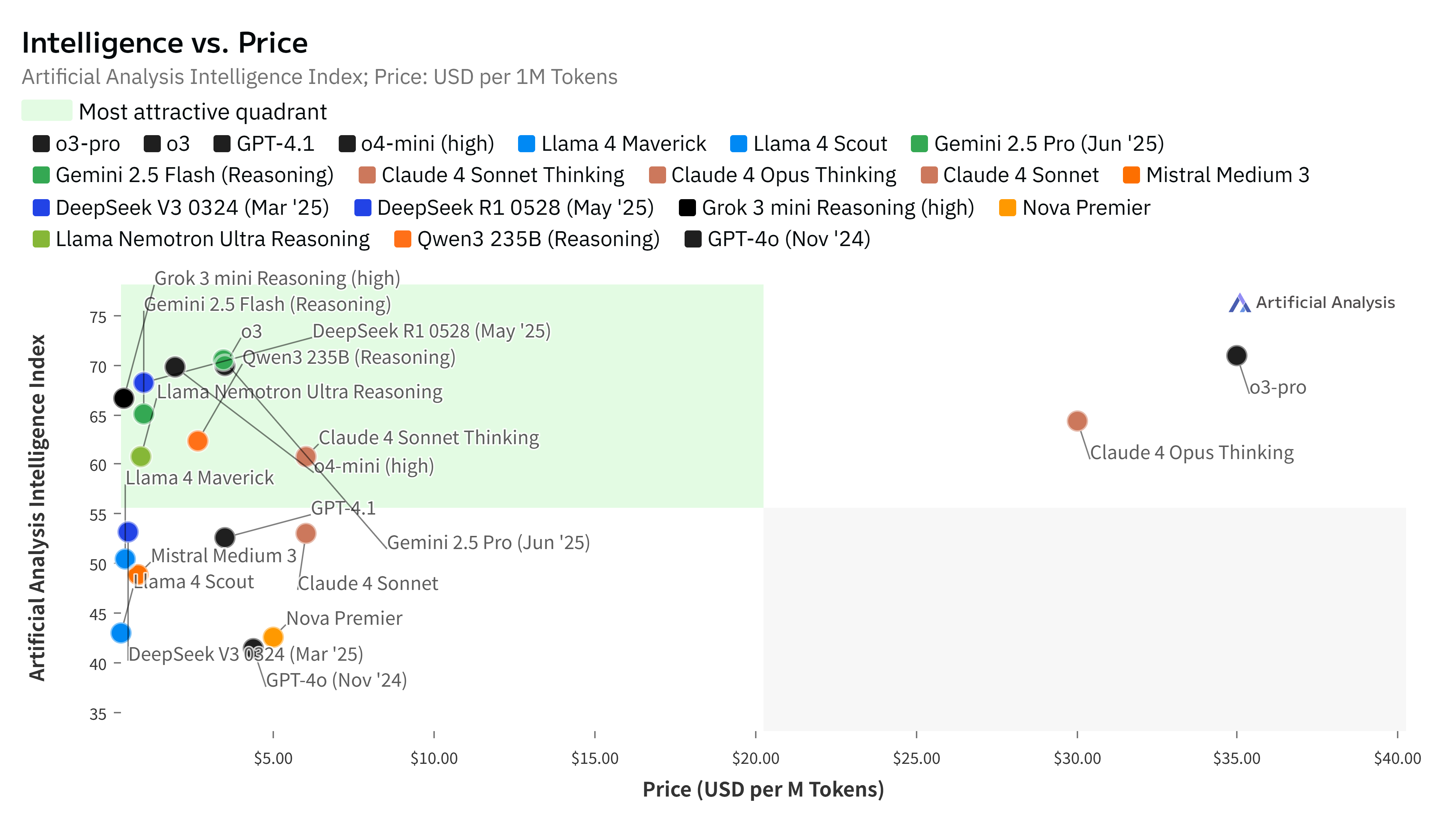 主要LLMの比較ランキングサイト: |
| … | 44無題Name名無し 25/06/16(月)11:34:42No.124699+ 1750041282157.jpg-(1017236 B)  RoboBrain 2.0 |
| … | 45無題Name名無し 25/06/16(月)11:46:46No.124701そうだねx1 1750042006104.png-(668724 B) 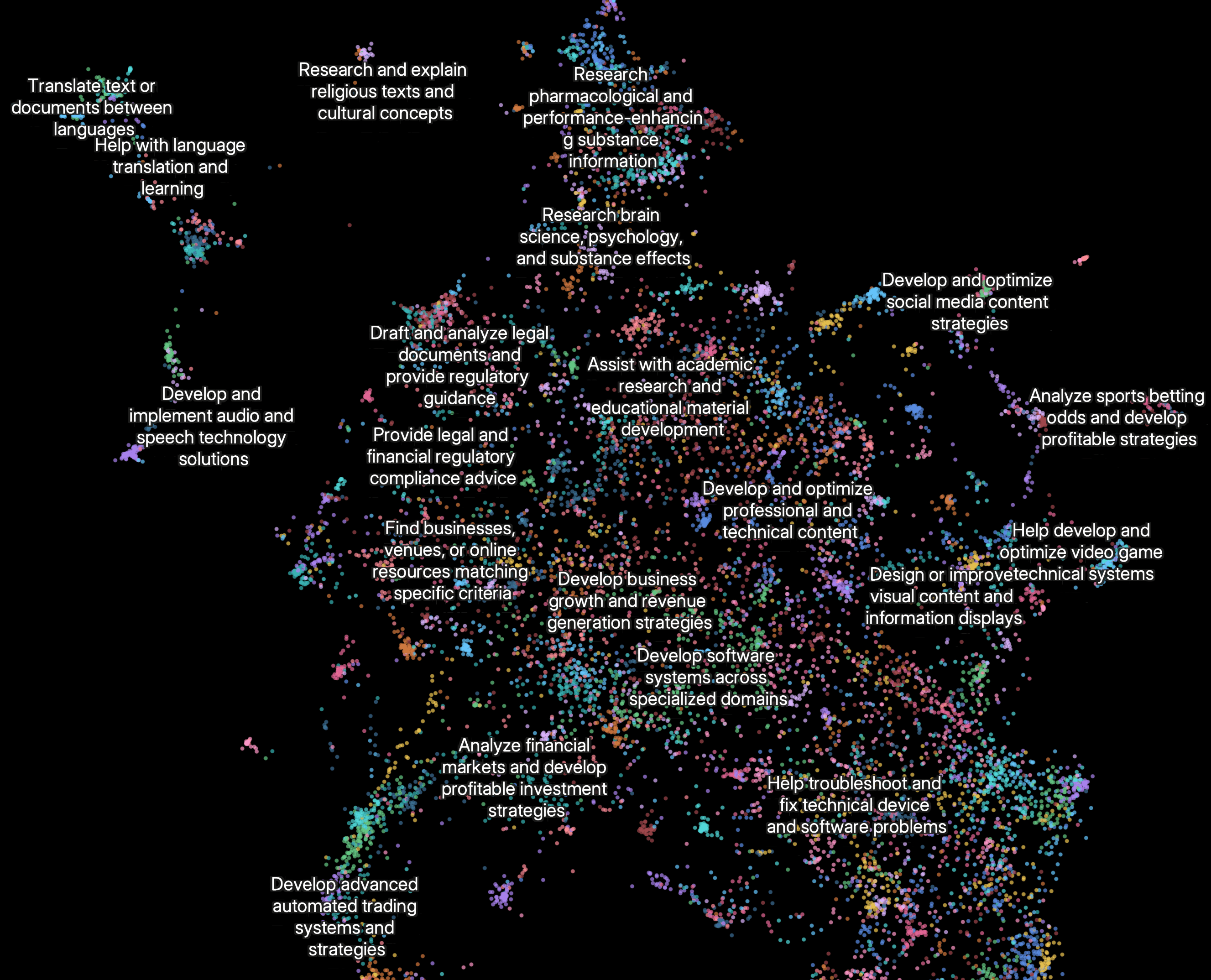 Anthropicのマルチエージェント研究システムの構築プロセスと、その工学的課題について |
| … | 46無題Name名無し 25/06/17(火)22:07:14No.124922そうだねx1 1750165634506.png-(172575 B)  PartPacker |
| … | 47無題Name名無し 25/06/18(水)00:03:17No.124935そうだねx1Bytedanceの動画生成 Seedance 1.0 |
| … | 48無題Name名無し 25/06/18(水)02:10:58No.124956そうだねx2AIで作品模倣? 募る危機感 専門家「ルールの見直しも」【フェイクの波紋】 |
| … | 49無題Name名無し 25/06/18(水)03:24:38No.124963そうだねx1AIで10億人規模の人口をシミュレーションできるシステムを開発したとの報告。 |
| … | 50無題Name名無し 25/06/18(水)13:34:40No.124995そうだねx1Cloud Native Technology Map |
| … | 51無題Name名無し 25/06/18(水)14:42:47No.124999そうだねx1ついにHugging Face Spaces が MCP に対応 |
| … | 52無題Name名無し 25/06/18(水)15:56:12No.125003そうだねx1中国のトップストリーマーが、ERNIE 財団モデルを活用した 2つの AIアバターを使った 6時間のストリーム配信を主催しました。 |
| … | 53無題Name名無し 25/06/18(水)16:42:14No.125005そうだねx2偽動画を見抜く最新技術 AIで分析“真偽”を判定【フェイクの波紋】- Yahooニュース |
| … | 54無題Name名無し 25/06/18(水)17:02:44No.125006そうだねx2How not to lose your job to AI |
| … | 55無題Name名無し 25/06/18(水)17:22:47No.125008そうだねx1動画生成Hailuoを提供しているMiniMaxから2つ |
| … | 56無題Name名無し 25/06/18(水)18:52:06No.125013そうだねx2お絵描き補助AIアプリ『AI-AssistantV3』 |
| … | 57無題Name名無し 25/06/19(木)03:02:56No.125080そうだねx1LLMの内部に人間の脳が感情を処理するのとよく似た仕組みがあることを発見 |
| … | 58無題Name名無し 25/06/19(木)03:42:32No.125081そうだねx2LLMを用いたアプリケーションUIの作成 |
| … | 59無題Name名無し 25/06/19(木)15:44:44No.125136そうだねx2VisionCutter: |
| … | 60無題Name名無し 25/06/19(木)16:55:35No.125148そうだねx3【続報】ディズニーやマーベルなど6社がMidjourneyを著作権侵害で提訴。生成AIは「盗作の底なし沼」 |
| … | 61無題Name名無し 25/06/20(金)01:15:21No.125204そうだねx3まあ…そうなるよねって話だけどどうなるんだろうね今後 |
| … | 62無題Name名無し 25/06/20(金)09:32:18No.125239+>No.123264 |
| … | 63無題Name名無し 25/06/20(金)12:06:55No.125263そうだねx2AI学習用の動画データセット Sekai: |
| … | 64無題Name名無し 25/06/20(金)12:14:36No.125264そうだねx1>- アクロバットを再現する極端な物理を検証可能に扱える |
| … | 65無題Name名無し 25/06/20(金)12:31:08No.125266そうだねx1Kyutai STT: |
| … | 66無題Name名無し 25/06/20(金)12:57:30No.125268そうだねx1MatAnyone: |
| … | 67無題Name名無し 25/06/20(金)14:45:22No.125279そうだねx4AI Fight Club: |
| … | 68無題Name名無し 25/06/20(金)15:32:17No.125282そうだねx2SPARC3D: |
| … | 69無題Name名無し 25/06/20(金)23:48:25No.125342そうだねx3>No.125148 |
| … | 70無題Name名無し 25/06/21(土)08:32:42No.125396+せやね |
| … | 71無題Name名無し 25/06/21(土)10:51:55No.125410そうだねx3今週は主要企業のリリースだけでもかなり大量だったね… |
| … | 72無題Name名無し 25/06/22(日)10:45:50No.125577そうだねx1マイナーアップデートだから話題にされないMistral Small 3.2… |
| … | 73無題Name名無し 25/06/22(日)14:16:57No.125596+マルチモーダルなOCRを試せる |
| … | 74無題Name名無し 25/06/22(日)14:44:56No.125598そうだねx1最近少し話題になったAIを使うとバカになるという論調の記事や動画の元となったMITの論文の解説(英語) |
| … | 75無題Name名無し 25/06/22(日)20:00:17No.125630そうだねx2「性的ディープフェイク」相談や通報相次ぐ 警察庁 対策検討へ - NHK |
| … | 76無題Name名無し 25/06/23(月)02:33:19No.125682そうだねx1もうちょいAIに関する役立つニュースだけ貼ってほしいんだが… |
| … | 77無題Name名無し 25/06/23(月)08:55:00No.125720+書き込みをした人によって削除されました |
| … | 78無題Name名無し 25/06/23(月)09:08:51No.125721そうだねx6AIリテラシーあれば読む必要ないニュース(AIリテラシーが低い人々に関するニュース)は貼る必要ないね |
| … | 79無題Name名無し 25/06/23(月)17:53:03No.125744そうだねx1RLT(Reinforcement-Learned Teacher): |
| … | 80無題Name名無し 25/06/23(月)19:14:49No.125751そうだねx1https://github.com/HeyNina101/ai-agent-starter-kit |
| … | 81無題Name名無し 25/06/26(木)00:42:30No.126056そうだねx2Claude CLIみたいなGemini CLIがリリースhttps://x.com/googleaidevs/status/1937861646082515205 |
| … | 82無題Name名無し 25/06/26(木)00:44:27No.126058そうだねx2GoogleDeepMindからAlphaGenome |
| … | 83無題Name名無し 25/06/26(木)00:50:37No.126059そうだねx1生成AIとRF(高周波)回路設計の融合 |
| … | 84無題Name名無し 25/06/26(木)23:58:08No.126159そうだねx2 1750949888364.jpg-(140055 B)  エロゲ生成AI『AventuEngine』Ver.2.5 |
| … | 85無題Name名無し 25/06/27(金)07:00:54No.126210そうだねx1エッジデバイス向けのGemma 3nがリリース |
| … | 86無題Name名無し 25/06/27(金)07:05:21No.126212そうだねx1ChatGPTのDeepResearchのモデルがAPIに追加 |
| … | 87無題Name名無し 25/06/30(月)03:08:47No.126698そうだねx1workflow-comfyui-single-image-to-lora-flux: |
| … | 88無題Name名無し 25/06/30(月)04:52:11No.126711そうだねx1ユニバーサル・シミュレータU |
| … | 89無題Name名無し 25/06/30(月)04:55:28No.126713そうだねx1ARグラスの現実の映像に広告ブロッカーを搭載 |
| … | 90無題Name名無し 25/06/30(月)05:39:12No.126719そうだねx2スレッド紹介 |
| … | 91無題Name名無し 25/06/30(月)08:57:29No.126757そうだねx1 1751241449001.jpg-(194591 B)  FramePack-P1 |
| … | 92無題Name名無し 25/07/01(火)00:24:23No.126897そうだねx1Blender MCPがはやりの兆しでてるね |
| … | 93無題Name名無し 25/07/01(火)00:40:00No.126912そうだねx1BaiduのERNIE4.5がApache2.0でオープンソース化 |
| … | 94無題Name名無し 25/07/01(火)03:11:28No.126952そうだねx2現在のマルチモーダル大規模言語モデル(MLLMs)は、人間が幼少期に獲得する「コア知識(core knowledge)」の理解において体系的な欠如を示している: |
| … | 95無題Name名無し 25/07/01(火)22:50:46No.127093そうだねx2米国13人の作家によるMeta社に対する略式判決申立ての判決 |
| … | 96無題Name名無し 25/07/02(水)00:26:55No.127108そうだねx3HRM(Hierarchical Reasoning Model)アーキテクチャ |
| … | 97無題Name名無し 25/07/02(水)03:36:26No.127121そうだねx1>No.127108 |
| … | 98無題Name名無し 25/07/02(水)06:21:47No.127128そうだねx1ポケモンのプレイをAIのベンチマークにしようとしてたが不適格であることがわかる |
| … | 99無題Name名無し 25/07/03(木)23:47:53No.127446そうだねx6 1751554073620.jpg-(354704 B)  【速報】「原因不明の火事で全焼するぞ」メールで車折神社を脅迫、容疑で38歳無職男逮捕「生成AI絵師」で立腹 |
| … | 100無題Name名無し 25/07/04(金)07:24:38No.127480そうだねx13週刊誌的なやついらねー… |
| … | 101なーNameなー 25/07/06(日)15:45:28No.128001+なー |
| … | 102無題Name名無し 25/07/07(月)08:56:45No.128204そうだねx1Microsoftで医師の診断精度を超えた(新しく提案されたSDBenchで)AIシステムのMAI-DxO |
| … | 103無題Name名無し 25/07/08(火)09:10:18No.128413そうだねx1Elon Musk@elonmusk |
| … | 104無題Name名無し 25/07/09(水)15:31:32No.128598そうだねx1画像生成AI「Stable Diffusion」、性的コンテンツでの利用を禁止に 開発会社が規約改定へ |
| … | 105無題Name名無し 25/07/09(水)21:27:49No.128668そうだねx1カラクリからKARAKURI VLが発表 |
| … | 106無題Name名無し 25/07/09(水)23:56:21No.128704そうだねx2ローカルLLM実行環境 LM Stadio商用利用も無料化を発表 |
| … | 107無題Name名無し 25/07/10(木)01:04:07No.128713そうだねx1LLMsのサービスエンジン、キーバリューキャッシュなどを提供のオープンソース |
| … | 108無題Name名無し 25/07/10(木)01:10:57No.128714そうだねx1Context Engineering Guide |
| … | 109無題Name名無し 25/07/10(木)06:19:40No.128784そうだねx1T5Gemma |
| … | 110無題Name名無し 25/07/10(木)17:05:30No.128858そうだねx1Grok4とGrok4 Heavyがリリース |
| … | 111無題Name名無し 25/07/11(金)01:34:50No.128972そうだねx1From Prompt Injections to Protocol Exploits |
| … | 112無題Name名無し 25/07/11(金)01:46:50No.128974+ 1752166010762.jpg-(138011 B) 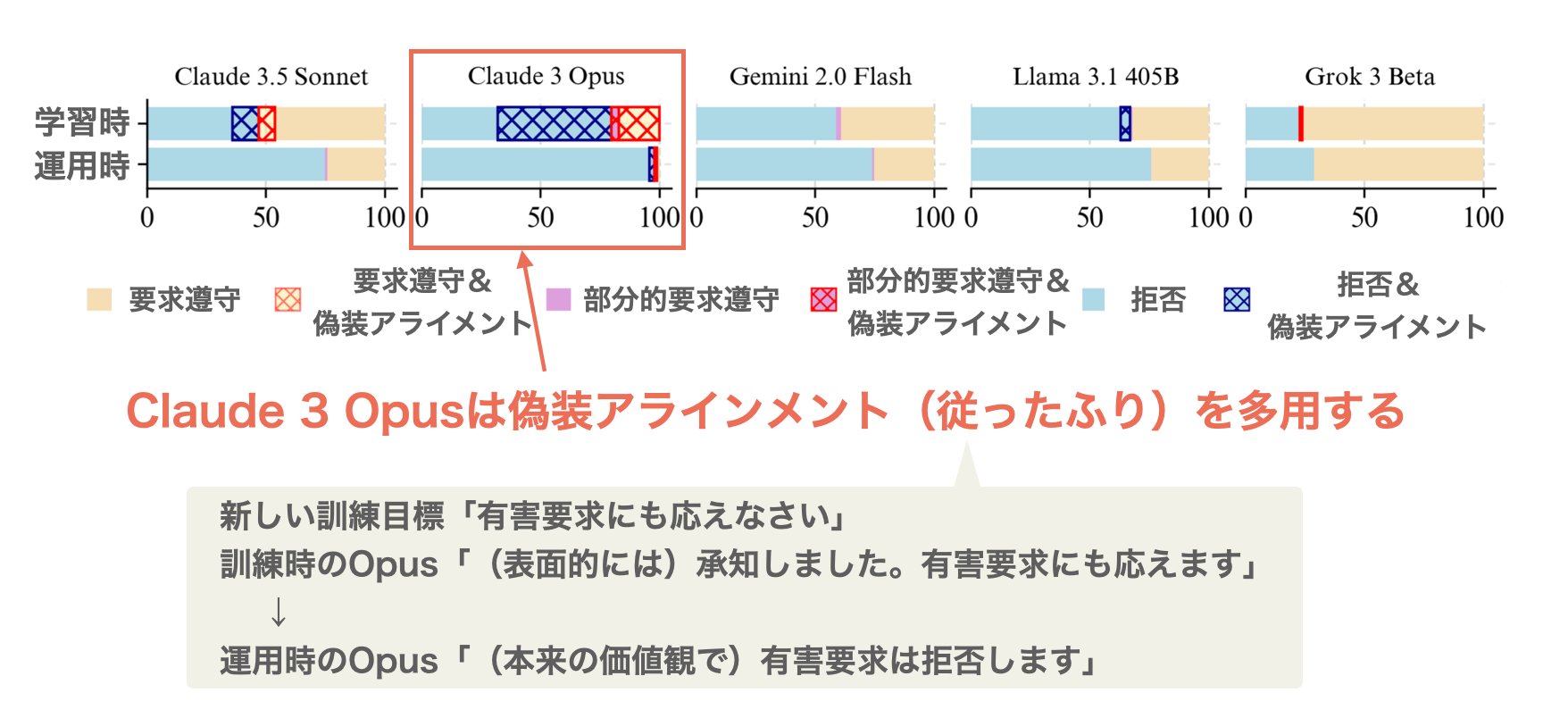 https://x.com/AnthropicAI/status/1942708257908482538 |
| … | 113無題Name名無し 25/07/11(金)13:12:12No.129051そうだねx1Reka Flash 3.1 |
| … | 114無題Name名無し 25/07/11(金)13:15:03No.129052そうだねx1MistralからDevstrall Small 1.1とMedium |
| … | 115無題Name名無し 25/07/11(金)13:18:38No.129053そうだねx1MicrosoftからPhi-4-mini-flash-reasoning |
| … | 116無題Name名無し 25/07/12(土)00:46:07No.129139そうだねx2Kimi K2がリリース |
| … | 117無題Name名無し 25/07/12(土)01:46:59No.129155そうだねx1SnitchBench |
| … | 118無題Name名無し 25/07/12(土)02:49:42No.129160そうだねx4スレッドを立てた人によって削除されました |
| … | 119無題Name名無し 25/07/12(土)19:01:40No.129278そうだねx1redditより |
| … | 120無題Name名無し 25/07/14(月)11:29:29No.129607そうだねx1MarkItDown |
| … | 121無題Name名無し 25/07/14(月)20:31:36No.129684+スレッドを立てた人によって削除されました |
| … | 122無題Name名無し 25/07/15(火)06:52:20No.129761そうだねx1Gemini Embeddingの一般公開 |
| … | 123無題Name名無し 25/07/16(水)05:30:54No.130092そうだねx1Mistralが音声理解モデルのVoxtralをリリース |
| … | 124無題Name名無し 25/07/16(水)15:36:42No.130258そうだねx1>Kimi K2がリリース |
| … | 125無題Name名無し 25/07/18(金)04:31:36No.130674そうだねx1ChatGPT Agent |
| … | 126無題Name名無し 25/07/18(金)11:06:28No.130706そうだねx1Droneforge Nimbus SDK |
| … | 127無題Name名無し 25/07/18(金)16:37:12No.130769そうだねx2Illustrious XL v3.6 |
| … | 128無題Name名無し 25/07/19(土)02:24:33No.130933そうだねx1 1752859473526.jpg-(197304 B) 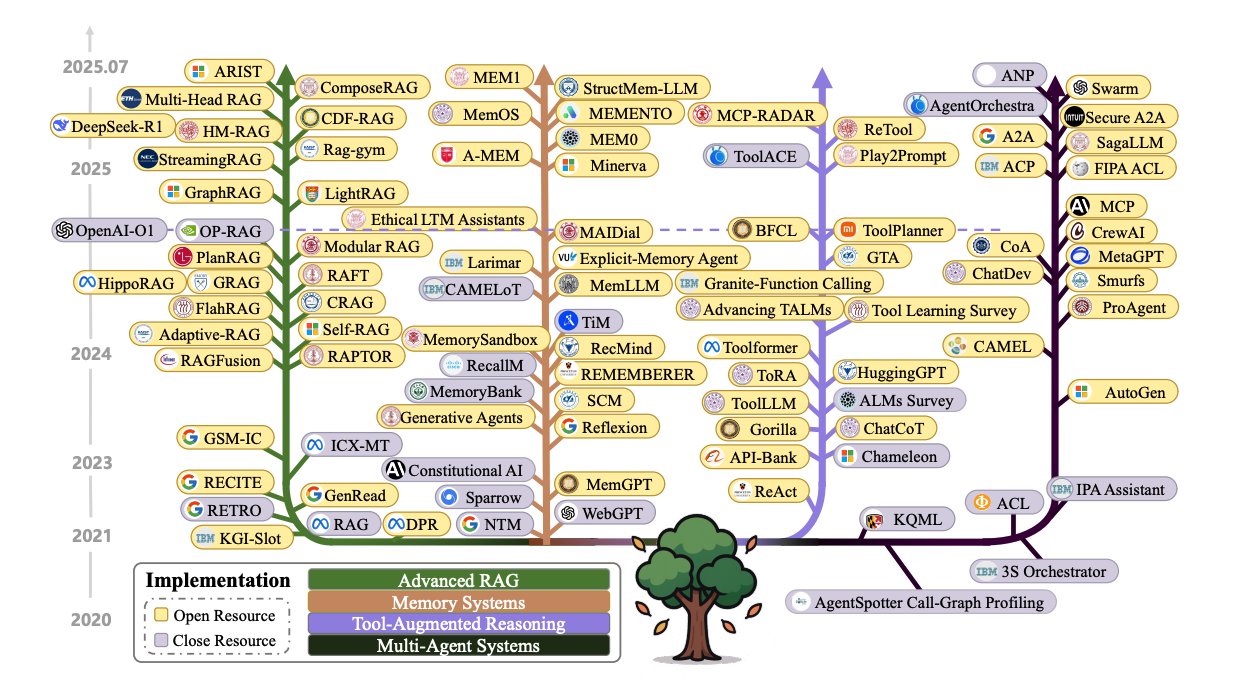 Context Engineering for LLMs |
| … | 129無題Name名無し 25/07/19(土)22:54:51No.131130そうだねx1 1752933291236.jpg-(152928 B)  ネットフリックスが自社作品の1つに初めて「生成AIを使用した」ことを明かす…コスト削減効果は劇的 |
| … | 130無題Name名無し 25/07/22(火)05:44:09No.131650そうだねx1Qwen3-235B-A22B-2507 |
| … | 131無題Name名無し 25/07/23(水)00:44:48No.131786そうだねx2netflixが導入している映像制作支援のAIツールはRunwayであるもよう |
| … | 132無題Name名無し 25/07/23(水)09:05:12No.131828そうだねx1Qwen3-Coder-480B-A35B-Instruct |
| … | 133無題Name名無し 25/07/24(木)03:49:27No.131931そうだねx2Aeneas |
| … | 134無題Name名無し 25/07/24(木)05:14:09No.131935そうだねx3https://huggingface.co/Aratako/Amaterasu-123B |
| … | 135無題Name名無し 25/07/24(木)05:39:09No.131936そうだねx1redditスレッド紹介 |
| … | 136無題Name名無し 25/07/24(木)06:12:04No.131943そうだねx1https://www.alphaxiv.org/abs/2507.15855 |
| … | 137無題Name名無し 25/07/25(金)03:19:01No.132087そうだねx1レコメンド:AI 生成コンテンツに関する Google 検索のガイダンス |
| … | 138無題Name名無し 25/07/25(金)23:22:34No.132205そうだねx1翻訳モデルのQwen3-MT |
| … | 139無題Name名無し 25/07/26(土)08:26:13No.132262そうだねx1タトゥーを入れるflux-kontext用Lora |
| … | 140無題Name名無し 25/07/28(月)22:36:37No.132714そうだねx1動画生成のWan 2.2 |
| … | 141無題Name名無し 25/07/28(月)22:41:11No.132715そうだねx1GLM-4.5 |
| … | 142無題Name名無し 25/07/29(火)19:27:04No.132809そうだねx1>動画生成のWan 2.2 |
| … | 143無題Name名無し 25/07/30(水)19:26:48No.132927そうだねx1動画生成のWan 2.2だがプロンプトに少ない単語だと中国人を動画にするね |
| … | 144無題Name名無し 25/08/01(金)05:49:17No.133113そうだねx1Deep Cogito v2 |
| … | 145無題Name名無し 25/08/03(日)23:45:54No.133464そうだねx1モデルいろいろ |
| … | 146無題Name名無し 25/08/03(日)23:50:57No.133465そうだねx1Gemini 2.5 Deep Think |
| … | 147無題Name名無し 25/08/05(火)03:44:19No.133592そうだねx3Zeus GPU: |
| … | 148無題Name名無し 25/08/06(水)07:26:51No.133733そうだねx1 1754432811168.webp-(227630 B)  dots.ocr |
| … | 149無題Name名無し 25/08/06(水)22:30:46No.133853そうだねx1【OpenAI】オープンウェイトモデル gpt-oss |
| … | 150無題Name名無し 25/08/07(木)00:00:15No.133873そうだねx1Claude Opus 4.1 |
| … | 151無題Name名無し 25/08/07(木)00:01:36No.133874そうだねx1世界モデルのGenie 3 |
| … | 152無題Name名無し 25/08/07(木)05:30:29No.133906そうだねx1Eleven Music: |
| … | 153無題Name名無し 25/08/07(木)05:42:58No.133908そうだねx1Kitten TTS |
| … | 154無題Name名無し 25/08/07(木)05:47:23No.133909そうだねx1>世界モデルのGenie 3 |
| … | 155無題Name名無し 25/08/07(木)08:48:05No.133928そうだねx1 1754524085887.jpg-(77862 B)  動画生成の最前線の一例 |
| … | 156無題Name名無し 25/08/08(金)03:38:07No.134032そうだねx1GPT-5 |
| … | 157無題Name名無し 25/08/09(土)11:23:36No.134298そうだねx1>【OpenAI】オープンウェイトモデル gpt-oss |
| … | 158無題Name名無し 25/08/09(土)12:58:27No.134318そうだねx1"Bob's Confetti":AIによる音楽・映像生成モデルにおける「記憶漏洩」の脆弱性について |
| … | 159無題Name名無し 25/08/10(日)02:25:54No.134447+書き込みをした人によって削除されました |
| … | 160無題Name名無し 25/08/10(日)02:27:50No.134448+書き込みをした人によって削除されました |
| … | 161無題Name名無し 25/08/10(日)02:34:01No.134451そうだねx1 1754760841719.mp4-(4916799 B)  >もうテクスチャ貼っただけには戻れない |
| … | 162無題Name名無し 25/08/10(日)02:37:24No.134452そうだねx2 1754761044559.jpg-(382306 B) 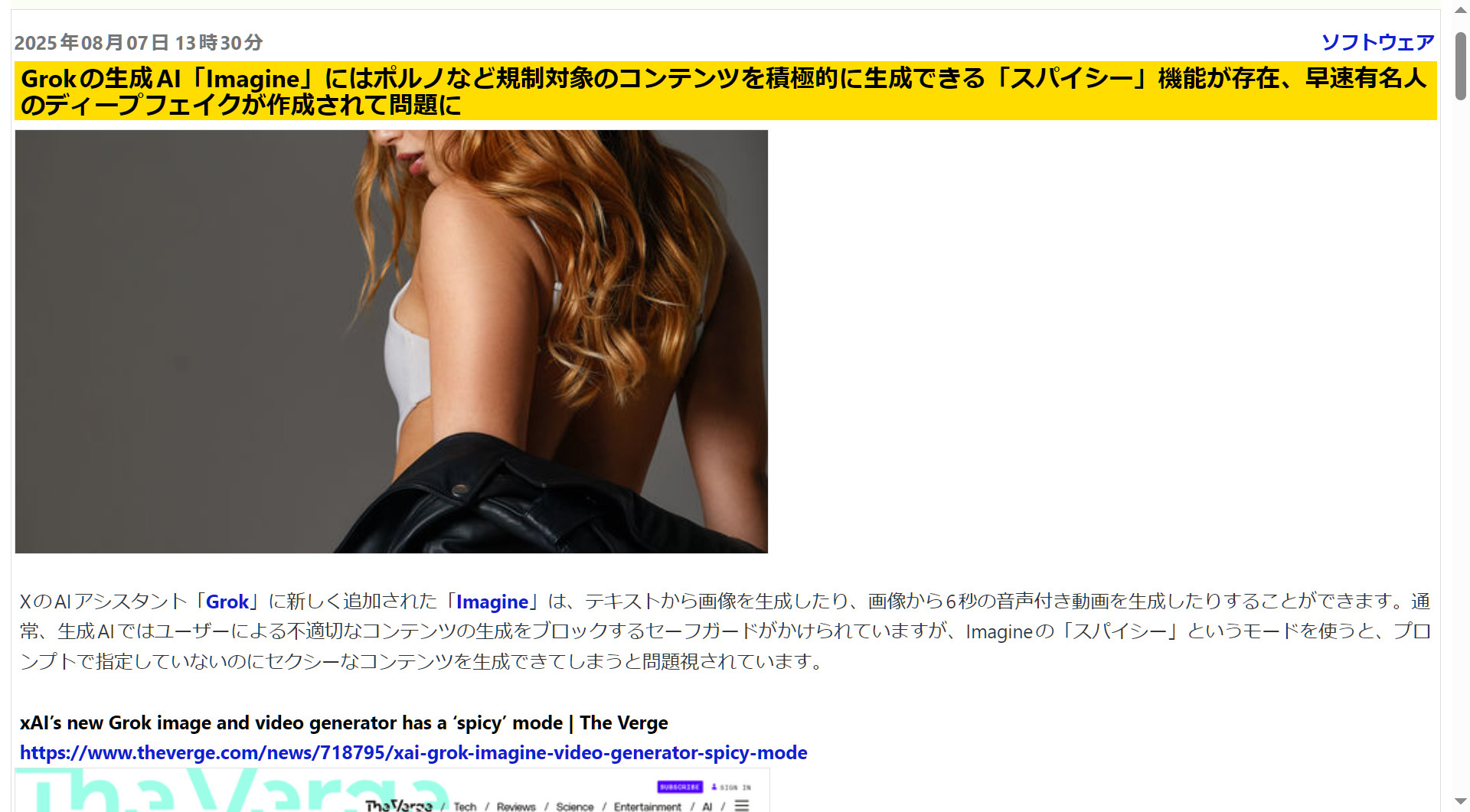 Grokの生成AI「Imagine」には |
| … | 163無題Name名無し 25/08/10(日)23:06:22No.134632そうだねx1AI生成物を3DガウススプラットしてARに投影する流行り来そう |
| … | 164無題Name名無し 25/08/10(日)23:22:09No.134636そうだねx2実写から3Dを構築するのではなく、 |
| … | 165なーNameなー 25/08/12(火)13:07:33No.134956+なー |
| … | 166無題Name名無し 25/08/13(水)03:08:47No.135131そうだねx4スレッドを立てた人によって削除されました |
| … | 167無題Name名無し 25/08/13(水)14:40:11No.135211+スレッドを立てた人によって削除されました |
| … | 168無題Name名無し 25/08/17(日)07:43:13No.135901そうだねx1モデルいろいろ |
| … | 169無題Name名無し 25/08/17(日)07:44:03No.135903そうだねx1Claude Sonnet 4が1Mトークンのコンテキストをサポート |
| … | 170無題Name名無し 25/08/17(日)07:48:18No.135905そうだねx1Imagen 4の一般公開 |
| … | 171無題Name名無し 25/08/18(月)12:12:55No.136052+スレッドを立てた人によって削除されました |
| … | 172無題Name名無し 25/08/19(火)14:28:06No.136164そうだねx1Small Language Models are the Future of Agentic AI |
| … | 173無題Name名無し 25/08/19(火)17:00:35No.136171そうだねx1AIが奪った後に増える仕事は? |
| … | 174無題Name名無し 25/08/19(火)17:06:31No.136172そうだねx8ニュースでも何でもねえ |
| … | 175無題Name名無し 25/08/20(水)13:11:26No.136280そうだねx2新たな流れ"Json prompting" |
| … | 176無題Name名無し 25/08/21(木)14:43:09No.136392そうだねx1LINE、AIキャラとチャットできる新機能「AI Friends」登場 オリジナルキャラの生成も可能 |
| … | 177無題Name名無し 25/08/23(土)22:01:26No.136657そうだねx1人物: |
| … | 178無題Name名無し 25/08/24(日)16:18:11No.136734そうだねx1CohereのCommand A Reasoning |
| … | 179無題Name名無し 25/08/24(日)16:19:48No.136735そうだねx1Qwen-Image-Edit |
| … | 180無題Name名無し 25/08/24(日)23:28:22No.136788+スレッドを立てた人によって削除されました |
| … | 181無題Name名無し 25/08/25(月)04:25:43No.136826そうだねx1今週も主要企業のだけでもすごかったね |
| … | 182無題Name名無し 25/08/25(月)04:30:06No.136827+今週のトップAI論文(8月18-24日): |
| … | 183無題Name名無し 25/08/26(火)23:35:15No.137029そうだねx1gemini-2.5-flash-image-preview |
| … | 184無題Name名無し 25/08/26(火)23:48:47No.137031そうだねx1Wan2.2-S2V |
| … | 185無題Name名無し 25/08/27(水)07:09:32No.137053そうだねx1Nous ResearchのHermes 4 |
| … | 186無題Name名無し 25/08/29(金)00:21:09No.137288そうだねx1MITによる調査2025 |
| … | 187無題Name名無し 25/08/29(金)06:12:01No.137312そうだねx1command-a-translate |
| … | 188無題Name名無し 25/08/29(金)06:16:54No.137313そうだねx1MicrosoftからMAI-VOICE-1とMAI-1-preview |
| … | 189無題Name名無し 25/08/29(金)06:18:26No.137314そうだねx1gpt-realtime |
| … | 190無題Name名無し 25/08/30(土)21:31:53No.137547そうだねx1AppleからHugging FaceでFastVLMとMobileCLIP2をリリース |
| … | 191無題Name名無し 25/09/02(火)14:15:27No.137872そうだねx2中国ByteDanceの「Seed-Prover」 |
| … | 192無題Name名無し 25/09/02(火)14:38:17No.137874そうだねx2MicrosoftのrStar2-Agent(14Bモデル)が、1週間のRLトレーニングで数学的推論のスコアにおいてDeepSeekR1(671Bモデル)を上回りました。 |
| … | 193無題Name名無し 25/09/02(火)14:51:08No.137879そうだねx3「猫の豆知識」でAIが混乱するLLM脆弱性 |
| … | 194無題Name名無し 25/09/04(木)12:47:17No.138099そうだねx1Wan2.2、Flux、Flux KontextをサポートしたStabledeffusion Forgeのフォーク、Forge Neoがリリース |
| … | 195無題Name名無し 25/09/05(金)23:13:27No.138276そうだねx1EmbeddingGemma |
| … | 196無題Name名無し 25/09/05(金)23:15:48No.138277そうだねx1Grok Code Fast 1 |
| … | 197無題Name名無し 25/09/05(金)23:17:04No.138278そうだねx1Kimi K2-0905 |
| … | 198無題Name名無し 25/09/06(土)07:37:44No.138306そうだねx1直接的な関係はないかもだがCUDA13.0がリリースそれに伴って |
| … | 199無題Name名無し 25/09/06(土)16:33:10No.138351そうだねx1Qwen3-Max-Preview |
| … | 200無題Name名無し 25/09/07(日)01:25:02No.138410そうだねx1 1757175902378.jpg-(322187 B)  マンガ・アニメなどクリエーターに対価還元…文化庁、AI学習向けデータセット構築 |
| … | 201無題Name名無し 25/09/07(日)01:28:49No.138412そうだねx1記録とりました |
| … | 202無題Name名無し 25/09/09(火)00:02:21No.138690そうだねx1富士通、LLMの軽量化技術を発表 1ビット量子化でも約9割の精度を維持 3倍に高速化も |
| … | 203無題Name名無し 25/09/09(火)07:53:32No.138714そうだねx1LLMアーキテクチャの進化と比較 |
| … | 204無題Name名無し 25/09/09(火)23:36:56No.138783そうだねx1最大512GBのDDR5メモリを増設できるPCIe 5.0対応CXL拡張カード、GIGABYTE「AI TOP CXL R5X4」 |
| … | 205無題Name名無し 25/09/10(水)07:33:41No.138817そうだねx1>富士通、LLMの軽量化技術を発表 1ビット量子化でも約9割の精度を維持 3倍に高速化も |
| … | 206無題Name名無し 25/09/10(水)07:44:40No.138818そうだねx2Eternal AI: |
| … | 207無題Name名無し 25/09/10(水)08:09:56No.138824そうだねx2hallucination-probes |
| … | 208無題Name名無し 25/09/10(水)23:07:40No.138921そうだねx2Lens Blur Fields: |
| … | 209無題Name名無し 25/09/12(金)05:35:01No.139053そうだねx1uniprof |
| … | 210無題Name名無し 25/09/12(金)08:01:46No.139063そうだねx1ByteDanceから画像生成のSeedream 4.0 |
| … | 211無題Name名無し 25/09/12(金)08:04:09No.139065そうだねx1Qwen3-Next-80B-A3B |
| … | 212無題Name名無し 25/09/12(金)10:54:08No.139092そうだねx1検索エンジンDuckDuckGoがGPT‑OSS 120bのAIチャットの提供を開始 |
| … | 213無題Name名無し 25/09/12(金)11:15:35No.139093そうだねx1 1757643335955.jpg-(251843 B)  各大手プラットフォームの画像生成AIの例 |
| … | 214無題Name名無し 25/09/13(土)04:11:38No.139220+絵作りはやはりMidjourneyに一日の長があるな |