 ����Name������25/09/20(�y)12:16:06No.140247��������x8
10��08:10�������܂�
����Name������25/09/20(�y)12:16:06No.140247��������x8
10��08:10�������܂�
AI�֘A�̃j���[�X�X�����̃X���͌Â��̂ŁA�������������܂��B
�����ĂȂ��悤�Ȃ̂�
�폜���ꂽ�L����15������܂�.����
| �c | 1����Name������ 25/09/20(�y)12:17:44No.140248��������x3Grok 4 Fast |
| �c | 2����Name������ 25/09/20(�y)14:48:28No.140266��������x3�O�X���L�^�B |
| �c | 3����Name������ 25/09/20(�y)16:05:36No.140270��������x2Wan2.2-Animate |
| �c | 4����Name������ 25/09/21(��)23:50:11No.140427��������x1IBM���J�������y�ʃ}���`���[�_�����f�� Granite-Docling-258M |
| �c | 5����Name������ 25/09/22(��)00:14:11No.140430��������x2MCP Toolbox for Databases |
| �c | 6����Name������ 25/09/23(��)03:03:05No.140550��������x4MalTerminal |
| �c | 7����Name������ 25/09/23(��)09:06:47No.140556��������x1�l�C�e�B�u�ȃI���j���[�_�����f����Qwen3-Omni |
| �c | 8����Name������ 25/09/23(��)09:08:41No.140557��������x1DeepSeek-V3.1-Terminus |
| �c | 9����Name������ 25/09/24(��)02:29:25No.140665��������x2Teaching LLMs to Plan |
| �c | 10����Name������ 25/09/24(��)06:17:43No.140670��������x2���f���[�V�����p��Qwen3Guard |
| �c | 11����Name������ 25/09/24(��)07:43:10No.140671��������x1Gemini Live���f�����A�b�v�f�[�g����gemini-2.5-flash-native-audio-preview-09-2025 |
| �c | 12����Name������ 25/09/25(��)02:41:36No.140761��������x1�uNemotron-Personas-Japan: Synthesized Data for Sovereign AI�v |
| �c | 13����Name������ 25/09/25(��)02:52:40No.140762��������x1 1758736360975.png-(151218 B)  ������C���^�[�l�b�g��AI Engine |
| �c | 14����Name������ 25/09/25(��)03:15:14No.140763��������x1awesome-ai-tools |
| �c | 15����Name������ 25/09/25(��)03:25:10No.140764��������x2>No.140556 |
| �c | 16����Name������ 25/09/25(��)03:38:53No.140765��������x1PlayCanvas Open Sources SOG: The WebP of Gaussian Splatting |
| �c | 17����Name������ 25/09/25(��)03:58:19No.140766��������x2gambo |
| �c | 18����Name������ 25/09/25(��)13:42:17No.140808+>https://www.gambo.ai/ |
| �c | 19����Name������ 25/09/25(��)17:23:21No.140819��������x2Moondream 3 |
| �c | 20����Name������ 25/09/25(��)22:15:52No.140840��������x1�Ɨ��s���@�l������i�@�\ �Z�L�����e�B�Z���^�[�� |
| �c | 21����Name������ 25/09/26(��)23:39:32No.140932��������x1Gemini 2.5 Flash��Flash-Lite�̃A�b�v�f�[�g |
| �c | 22����Name������ 25/09/26(��)23:40:52No.140933��������x1Gemini Robotics 1.5 |
| �c | 23����Name������ 25/09/26(��)23:56:25No.140935��������x2 1758898585513.jpg-(77722 B)  ���E���I���{���(�������I.Y.P Consulting)��GPU��s�v�Ƃ��鐶��AI (LLM) �̊J���ɐ����B�^2025�N10��10���̓s���C�x���g�Ő�s���\ |
| �c | 24����Name������ 25/09/27(�y)00:05:14No.140936��������x1AnimeGen�i���́j |
| �c | 25����Name������ 25/09/27(�y)00:06:08No.140938��������x2�����̌ÓT�I��SVM�ł��������ɂ���Ă͓����Ƃ�����W�߂���Ȃ� |
| �c | 26����Name������ 25/09/27(�y)01:49:45No.140945��������x1oLLM |
| �c | 27����Name������ 25/09/27(�y)05:53:01No.140966��������x1>���E������LLM�i��K�͌��ꃂ�f���j�쓮�^�}���E�F�A�̈��Ƃ����B |
| �c | 28����Name������ 25/09/27(�y)16:55:56No.141021��������x1 1758959756235.png-(110941 B)  Sparse VideoGen2�iSVG2�j |
| �c | 29����Name������ 25/09/27(�y)17:16:18No.141023��������x1 1758960978537.webp-(233256 B)  Craftwerk |
| �c | 30����Name������ 25/09/27(�y)18:24:26No.141025��������x1The Illusion of Readiness�u�}���`���[�_����Ãx���`�}�[�N�ɂ������K�͍Ő�[���f���̃X�g���X�e�X�g�v |
| �c | 31����Name������ 25/09/27(�y)23:35:44No.141046��������x2 1758983744876.jpg-(500560 B)  SD3.5-Flash |
| �c | 32����Name������ 25/09/27(�y)23:54:15No.141048��������x1Suno V5 |
| �c | 33����Name������ 25/09/28(��)00:15:05No.141051��������x1Unsloth AI��Google colab�̖����g�iT4�Ȃǁj�ł�GPT-oss(20B)�̃g���[�j���O���\��notebook��z�z�� |
| �c | 34����Name������ 25/09/28(��)04:14:55No.141067��������x1google Veo3�̘_�� |
| �c | 35����Name������ 25/09/29(��)01:38:05No.141188+����ꂽ�d�͂���V�X�e���S�̂��ǂꂾ���̃g�[�N�������i��o�����H�Ƃ��������̃t�F�[�Y�ɂȂ��Ă��āA�P��̃`�b�v�̐��\�≿�i(���ɖ����ł����Ă�)����ΓI�ȗD�ʐ��ɂ͂Ȃ�Ȃ��A��nVidia��ceo����� |
| �c | 36����Name������ 25/09/29(��)10:39:27No.141217+��������3090�����Ďg���邯�� |
| �c | 37����Name������ 25/09/29(��)12:43:51No.141221+>��������3090�����Ďg���邯�� |
| �c | 38����Name������ 25/09/29(��)21:49:38No.141290��������x1Craft-GPT |
| �c | 39����Name������ 25/09/29(��)23:32:50No.141308��������x4�O���{�Ȃ�Ă��̂��������Ȃ������ɔ����Ηǂ��B |
| �c | 40����Name������ 25/09/30(��)00:05:53No.141315��������x1DeepSeek-V3.2-Exp |
| �c | 41����Name������ 25/09/30(��)05:33:27No.141340��������x1Claude Sonnet 4.5 |
| �c | 42����Name������ 25/09/30(��)10:52:03No.141370+��������Claude Sonnet 4.5�̃V�X�e���v�����v�g�炵�����̂��R�ꂽ�炵���B |
| �c | 43����Name������ 25/09/30(��)19:11:24No.141400��������x2�j���[�X�Ƃ����킯�ł͂Ȃ����AAI�e�b�N�J���t�@�����X����AI��2025�̈ꕔ�Ƃ��āuAI�N���G�C�e�B�u�R���e�X�g2025�v�� ���܍�i���\���ꂽ |
| �c | 44����Name������ 25/09/30(��)20:32:32No.141403��������x3Z.ai��GLM��4.6�ɃA�b�v�f�[�g |
| �c | 45����Name������ 25/09/30(��)20:47:12No.141407��������x1Ring-1T-preview |
| �c | 46����Name������ 25/09/30(��)23:02:26No.141426��������x1>No.141403 |
| �c | 47����Name������ 25/10/01(��)00:07:43No.141436��������x1�C�[������xAI��Grokipedia(Wekipedia�N���[���H)�����������Ɣ��� |
| �c | 48����Name������ 25/10/01(��)00:19:24No.141442��������x1>Ring-1T-preview |
| �c | 49����Name������ 25/10/01(��)04:41:09No.141467+�������݂������l�ɂ���č폜����܂��� |
| �c | 50����Name������ 25/10/01(��)04:48:00No.141468��������x2OpenAI�����搶��AI�ł���Sora2�\ |
| �c | 51����Name������ 25/10/01(��)18:05:22No.141524��������x1Alibaba��NVIDIA�݊�AI�`�b�v�̌݊�����PyTorch�Ή����x������Ȃ����Ƃ����L�� |
| �c | 52����Name������ 25/10/02(��)05:20:49No.141608+>OpenAI�����搶��AI�ł���Sora2�\ |
| �c | 53����Name������ 25/10/02(��)14:56:18No.141627��������x5Sora2����˂��� |
| �c | 54����Name������ 25/10/02(��)16:49:35No.141628+>Sora2����˂��� |
| �c | 55����Name������ 25/10/02(��)23:45:47No.141676��������x2�������w�������ɂ������K�͌��ꃂ�f���\�z�ւ̋��͂ɂ��� |
| �c | 56����Name������ 25/10/03(��)03:52:42No.141697��������x1�L�I�N�V�A�A�uNVIDIA�̗v�]�v��100�{��SSD�J���@AI�T�[�o�[���� |
| �c | 57����Name������ 25/10/04(�y)15:27:01No.141865��������x3Sora2�������Ȃ�K���������݂������ˁA�����܂Ń��[�U�[�ڐ������� |
| �c | 58����Name������ 25/10/04(�y)20:49:07No.141895+ChatGPT�͊��S�ɃG���l�^�_���ɂȂ��� |
| �c | 59����Name������ 25/10/05(��)19:43:29No.142048��������x1Tencent��Hunyuan Image 3.0 |
| �c | 60����Name������ 25/10/05(��)19:48:33No.142053��������x1Seedream 4.0 |
| �c | 61����Name������ 25/10/05(��)19:56:35No.142054��������x1Alibaba��Wan2.5-Preview |
| �c | 62����Name������ 25/10/06(��)01:19:56No.142115��������x2LMArena�̕]���������Ă����ԃn�b�N����Ă銴�������ǂ��Ȃ�ł��傤�ˁc |
| �c | 63����Name������ 25/10/06(��)02:32:37No.142118��������x1�x���`�͂���������ۂɎg�킹�Ă�����Ă��� |
| �c | 64����Name������ 25/10/07(��)00:39:12No.142219+Sora 2�ł������ȓ�������������o�͂���v�����v�g���L�X���͂ǂ������� |
| �c | 65����Name������ 25/10/07(��)12:36:36No.142262��������x1sora2�X���ł����̂ł����������Ƃ��� |
| �c | 66����Name������ 25/10/08(��)05:48:11No.142384��������x1Gemini 2.5 Computer Use model |
| �c | 67����Name������ 25/10/09(��)05:10:38No.142497��������x1ChatGPT Apps SDK |
| �c | 68����Name������ 25/10/09(��)13:23:25No.142541��������x1 1759983805907.jpg-(147427 B)  �u���[���o�[�O�ɂ��AI�֘A�̎����z�̂܂Ƃ� |
| �c | 69����Name������ 25/10/09(��)15:26:50No.142545��������x1�T���\���d�q ���^AI���f���uTRM�v�\ |
| �c | 70����Name������ 25/10/09(��)16:03:38No.142546��������x1codemender |
| �c | 71����Name������ 25/10/09(��)20:32:57No.142577��������x2���[�J��LLM �̃����[�X�N�\ |
| �c | 72����Name������ 25/10/10(��)05:05:20No.142633��������x1�uAI�A�j���v�����KaKa Creation�A4��5000���~�B�@�A�~���[�Y��MIXI�Ȃ�9�Ђ��� |
| �c | 73����Name������ 25/10/10(��)07:52:01No.142636��������x1AI�����������t�B�b�V���O���[�������ʂł����l��46���A1.8���l�ɒ��� |
| �c | 74����Name������ 25/10/10(��)17:56:37No.142678+���Șb���˂� |
| �c | 75����Name������ 25/10/10(��)23:51:51No.142739+�t�F�C�N���������ɂ�AI����ɕK�v�ɂȂ��Ă����킯�� |
| �c | 76����Name������ 25/10/11(�y)16:28:45No.142829��������x1Google Research���J�������V�������������Z�p�uSpeech-to-Retrieval�iS2R�j |
| �c | 77����Name������ 25/10/11(�y)17:23:50No.142832��������x1Kwaipilot�ɂ��ŐV�̑�K�͌��ꃂ�f�� KAT-Dev-72B-Exp |
| �c | 78����Name������ 25/10/11(�y)19:02:24No.142844��������x1�����A���A�A�[�X�Z�p�̗A�o�K�����\ |
| �c | 79����Name������ 25/10/12(��)09:54:33No.142924��������x1Nexa AI��Snapdragon���ڂ̃X�}�z(RAM 16GB��)��GPT-OSS 20B�����[�J���ɓ�������Ɣ��\���� |
| �c | 80����Name������ 25/10/15(��)03:49:41No.143405��������x1NVIDIA��NVFP4�ƌĂ��4�r�b�g���x��12B�p�����[�^�̌��ꃂ�f���x�Ȃ����ƂȂ���K�͂Ȏ��O�g���[�j���O�𐬌������� |
| �c | 81����Name������ 25/10/15(��)04:43:23No.143409��������x1Python3.14�փo�[�W�����A�b�v |
| �c | 82����Name������ 25/10/15(��)05:01:12No.143410��������x1StreamingVLM |
| �c | 83����Name������ 25/10/15(��)08:12:34No.143417��������x2ComfyUI��nVidia���̏��^AI�X�p�R���uDGX Spark�v��œ��삷��i�����T�|�[�g�j�Ɣ��\ |
| �c | 84����Name������ 25/10/15(��)11:20:15No.143432+>No.143417 |
| �c | 85����Name������ 25/10/15(��)12:20:52No.143440��������x1LPDDR5x�������̑ш�i�ő�273GB/s�j�̃{�g���l�b�N���ǂ��l���邩�H�œK�����������H�Ƃ����c�_���C�O�ł���Ă邯�Ǘp�r����ł͈������� |
| �c | 86����Name������ 25/10/15(��)17:17:54No.143459��������x1���ߐt ����HF�݊��z�X�e�B���O�T�[�r�X��KohakuHub���\�z�\ |
| �c | 87����Name������ 25/10/16(��)01:19:04No.143571��������x1Veo3.1 |
| �c | 88����Name������ 25/10/16(��)05:57:27No.143587��������x1Claude Haiku 4.5 |
| �c | 89����Name������ 25/10/16(��)07:36:21No.143590��������x1PyTorch 2.9 Release |
| �c | 90����Name������ 25/10/16(��)07:48:21No.143591��������x1RAEs�i Representation AutoEncoders�j |
| �c | 91����Name������ 25/10/16(��)19:56:06No.143663��������x1Google Research���J�������@�B�w�K�A�N�Z�����[�^�uCoral NPU�v���I�[�v���\�[�X�� |
| �c | 92����Name������ 25/10/16(��)21:32:10No.143671+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 93����Name������ 25/10/17(��)03:40:11No.143715��������x1 1760640011635.jpg-(287173 B) 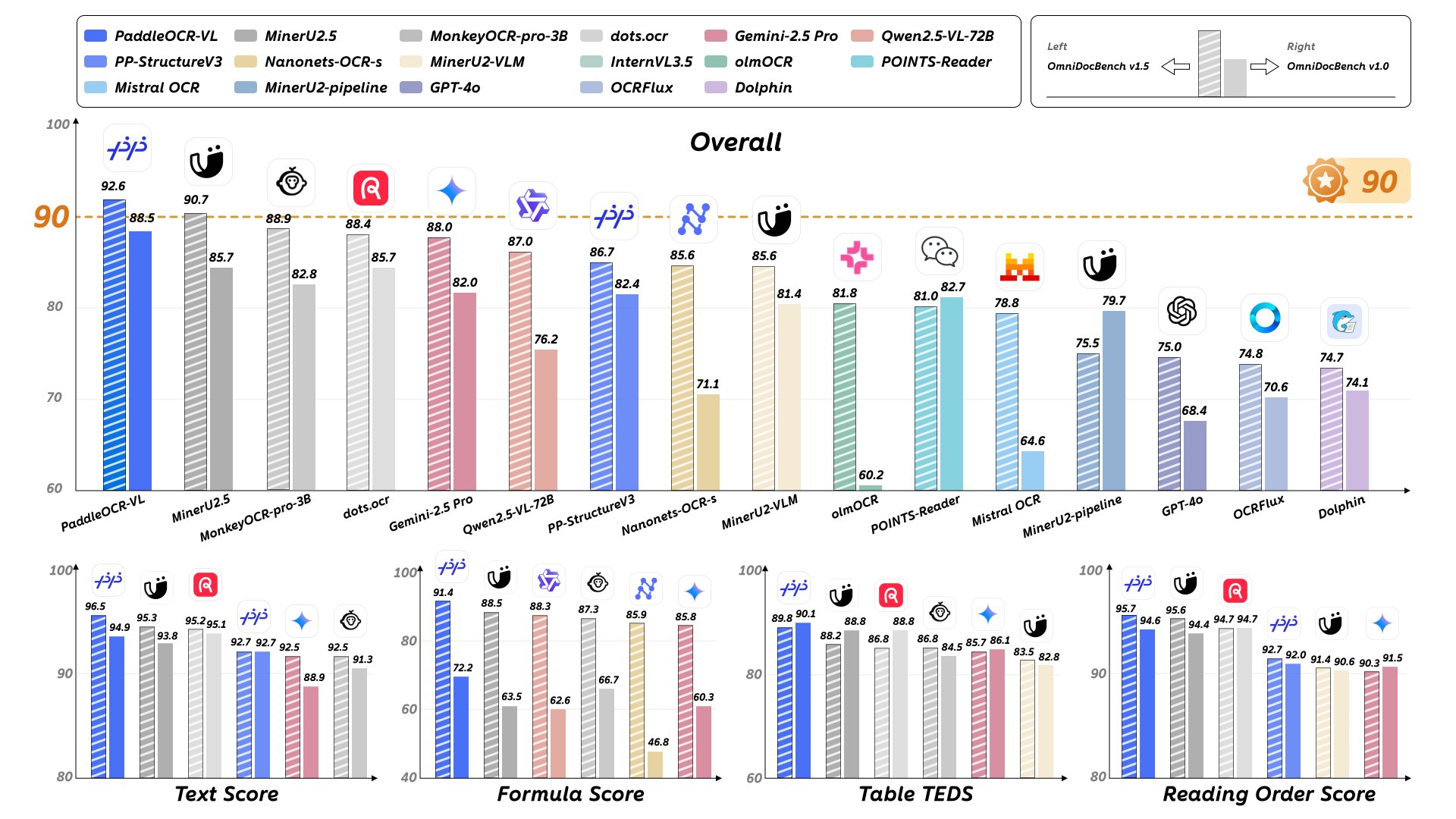 PaddleOCR-VL |
| �c | 94����Name������ 25/10/17(��)05:33:12No.143723��������x1vLLM TPU |
| �c | 95����Name������ 25/10/17(��)05:41:43No.143725��������x1 1760647303359.jpg-(435159 B)  Apple M4 MAX + GDX Spark x2�Ƃ������]�ؕҐ��D�� |
| �c | 96����Name������ 25/10/17(��)06:03:56No.143726��������x1MSI�ANVIDIA GB10���ڂ�AI�J���Ҍ����~�jPC�B�ő�2,000���p�����[�^��AI���f���ɑΉ� |
| �c | 97����Name������ 25/10/17(��)06:31:16No.143731��������x1AnyUp |
| �c | 98����Name������ 25/10/18(�y)18:50:12No.143896��������x1 1760781012916.png-(138928 B) 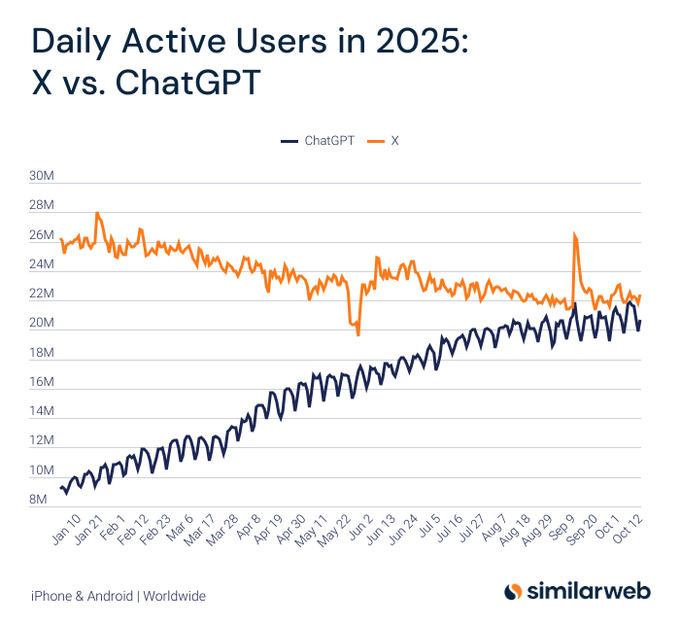 similarweb�̒��ׂɂ��ƃA�N�Z�X����ChatGPT��X��ǂ��������Ƃ��Ă��邻���� |
| �c | 99����Name������ 25/10/18(�y)19:20:30No.143900��������x1Verbalized Sampling |
| �c | 100����Name������ 25/10/18(�y)20:13:13No.143905��������x2 1760785993456.jpg-(92910 B)  Alpha Arena�ɂ�6��AI���f�������ꂼ��1���h�������S�Ɏ����I�Ɏ�����郉�C�u�x���`�}�[�N���J�� |
| �c | 101����Name������ 25/10/19(��)22:08:47No.144074��������x2VideoLingo |
| �c | 102����Name������ 25/10/21(��)19:03:07No.144334��������x2DeepSeek-OCR |
| �c | 103����Name������ 25/10/22(��)04:55:22No.144411��������x1>DeepSeek-OCR |
| �c | 104����Name������ 25/10/22(��)05:33:02No.144413��������x2https://huggingface.co/Phr00t/WAN2.2-14B-Rapid-AllInOne/tree/main/Mega-v8 |
| �c | 105����Name������ 25/10/22(��)06:54:53No.144414��������x2Minisforum����uMS-S1 MAX�v |
| �c | 106����Name������ 25/10/24(��)23:16:05No.144737��������x3WorldMirror |
| �c | 107����Name������ 25/10/25(�y)21:51:51No.144845��������x1Pico-Banana-400K�F |
| �c | 108����Name������ 25/10/25(�y)23:28:37No.144860��������x1 1761402517296.jpg-(42336 B) 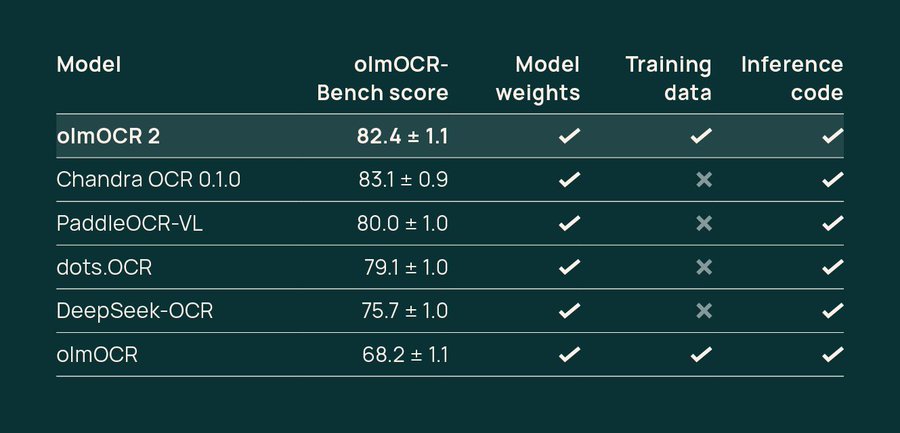 olmOCR 2�F |
| �c | 109����Name������ 25/10/25(�y)23:54:14No.144867��������x1A1111��Portable�ŁiPython3.11.13�j |
| �c | 110����Name������ 25/10/26(��)00:45:57No.144876��������x1https://aistudynow.com/sora-2-in-comfyui-workflow-how-i-generated-a-free-15-sec-ai-video/ |
| �c | 111����Name������ 25/10/26(��)06:11:31No.144899��������x3>https://aistudynow.com/sora-2-in-comfyui-workflow-how-i-generated-a-free-15-sec-ai-video/ |
| �c | 112����Name������ 25/10/26(��)13:23:47No.144928��������x1ImpossibleBench: |
| �c | 113����Name������ 25/10/27(��)17:59:19No.145096��������x1Audio Flamingo 3 |
| �c | 114����Name������ 25/10/28(��)03:07:30No.145159��������x1LLMs can hide text in other text of the same length |
| �c | 115����Name������ 25/10/28(��)05:56:08No.145166��������x1 1761598568767.jpg-(160190 B)  �{�j�[�s���N�̐V�ȁuLike Gravity�vMV� |
| �c | 116����Name������ 25/10/28(��)10:34:44No.145201��������x1MiniMax���MiniMax M2�������[�X |
| �c | 117����Name������ 25/10/28(��)18:24:54No.145213��������x2>�E�B���ꂽ�e�L�X�g�ƌ�������̃e�L�X�g�́ALLM�̃g�[�N���P�ʂœ��������B����ɂ��A�����ڂł͂ǂ��炪�{�������ʂł��Ȃ��B |
| �c | 118����Name������ 25/10/29(��)00:26:05No.145256��������x1MoCha |
| �c | 119����Name������ 25/10/29(��)00:39:30No.145258��������x1NANO3D |
| �c | 120����Name������ 25/10/29(��)04:15:10No.145273+�������݂������l�ɂ���č폜����܂��� |
| �c | 121����Name������ 25/10/29(��)04:16:35No.145274��������x1TOON |
| �c | 122����Name������ 25/10/30(��)15:35:51No.145382��������x1Brumby-14B-Base |
| �c | 123����Name������ 25/10/30(��)23:41:43No.145418��������x1drFonts |
| �c | 124����Name������ 25/10/31(��)00:05:09No.145423��������x1Universal Music Group�iUMG�j��AI���y�����v���b�g�t�H�[��Udio���A�ƊE���̐헪�I��g�\�F |
| �c | 125����Name������ 25/10/31(��)00:18:57No.145425+Stability AI��Universal Music Group�iUMG�j��EA�ƒ�g�����݂��������� |
| �c | 126����Name������ 25/10/31(��)02:51:27No.145444��������x1 1761846687762.jpg-(139915 B) 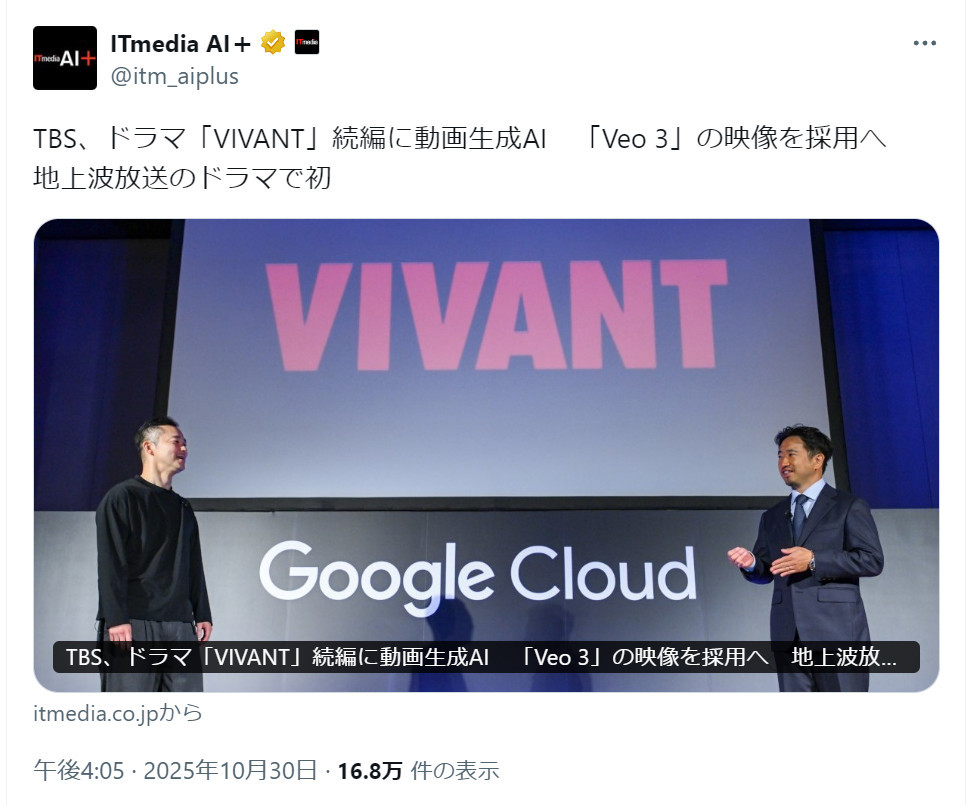 TBS�A�h���}�uVIVANT�v���҂ɓ��搶��AI�@�uVeo 3�v�̉f�����̗p�ց@�n��g�����̃h���}�ŏ� |
| �c | 127����Name������ 25/10/31(��)04:34:20No.145445��������x2LTX-2 |
| �c | 128����Name������ 25/11/02(��)03:31:42No.145684��������x4>drFonts |
| �c | 129����Name������ 25/11/05(��)21:08:24No.146070��������x1�R�J�E�R�[���@�N���X�}�X�L���@2024 vs 2025 |
| �c | 130����Name������ 25/11/07(��)10:53:28No.146216��������x2iPhone��GPT-OSS 20B |
| �c | 131����Name������ 25/11/10(��)00:01:24No.146501��������x1MIDI-LLM |
| �c | 132����Name������ 25/11/10(��)01:30:21No.146511��������x1File Search Tool |
| �c | 133����Name������ 25/11/10(��)01:46:01No.146514��������x1Cache-to-Cache |
| �c | 134����Name������ 25/11/10(��)02:11:35No.146515��������x3 1762708295911.jpg-(151265 B)  11/9�A������AI�c�[���v���b�g�t�H�[���Ő����Ԃɂ킽���ČÂ��`�F�b�N�|�C���g�o�[�W�����i�����{�Łj��NanoBanana2�����[�N����Ă����������B |
| �c | 135����Name������ 25/11/11(��)15:39:30No.146625��������x1 1762843170780.png-(111028 B) 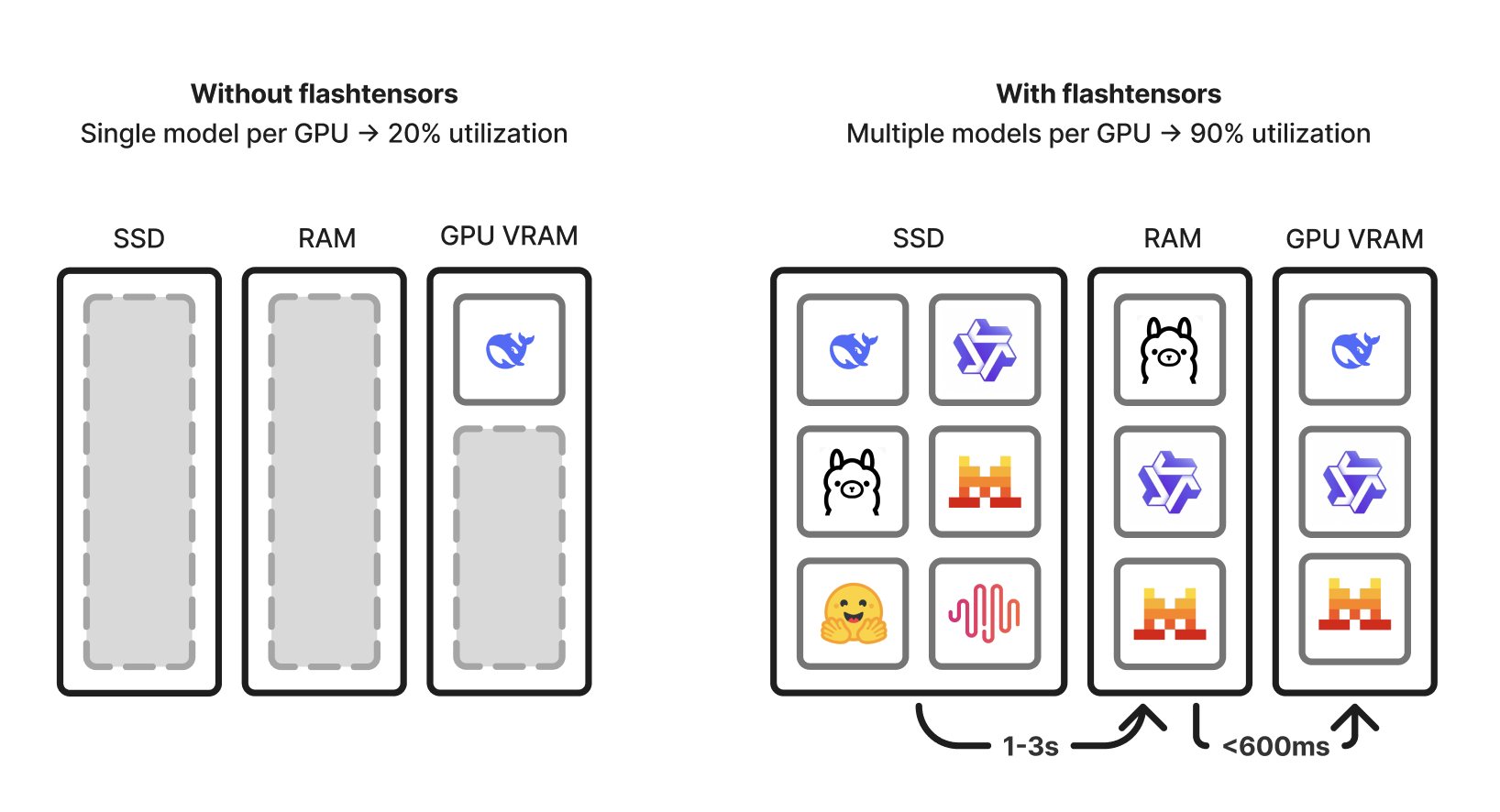 flashtensors |
| �c | 136����Name������ 25/11/12(��)05:26:05No.146688��������x2Mixboard |
| �c | 137����Name������ 25/11/12(��)15:20:25No.146704��������x3>No.146688 |
| �c | 138����Name������ 25/11/13(��)21:20:25No.146775��������x2OpenAI�A�h�C�c�ł̒��쌠�N�Q�i�ׂŔs�i�i���R�́u���f�w�K�v�ł͂Ȃ��j |
| �c | 139����Name������ 25/11/14(��)00:26:25No.146795��������x4 1763047585843.mp4-(6355013 B)  AI�L�����ƌ����Ɍ�������32�Γ��{�l���� |
| �c | 140����Name������ 25/11/14(��)15:35:08No.146823��������x4���łɎn�܂��Ă���AI�T�C�o�[�푈 |
| �c | 141����Name������ 25/11/15(�y)00:57:18No.146852��������x4>No.146795 |
| �c | 142����Name������ 25/11/18(��)20:12:20No.147141��������x1���f�������[�X���낢�� |
| �c | 143����Name������ 25/11/18(��)20:15:39No.147143��������x1OpenAI�n |
| �c | 144����Name������ 25/11/18(��)20:17:00No.147144��������x2Grok 4.1 |
| �c | 145����Name������ 25/11/19(��)07:04:11No.147195��������x2Gemini3 |
| �c | 146����Name������ 25/11/20(��)13:14:36No.147340��������x2GPT-5.1 Pro�����[���A�E�g |
| �c | 147����Name������ 25/11/20(��)18:06:36No.147353��������x2�Ȃ�ł��Z�O�����g���f����SAM 3 |
| �c | 148����Name������ 25/11/21(��)00:42:18No.147386��������x3Nano Banana Pro�������[�X |
| �c | 149����Name������ 25/11/21(��)13:09:30No.147417��������x2>Nano Banana Pro�������[�X |
| �c | 150����Name������ 25/11/24(��)21:36:31No.147751��������x2Google���uAttention is all you need (V2)�v�Ƃ�������_���\ |
| �c | 151����Name������ 25/11/25(��)07:47:54No.147807��������x2Claude Opus 4.5 |
| �c | 152����Name������ 25/11/25(��)21:20:11No.147853��������x2LeagueOfLegends��Grork�v���`�[����2026�N���ɍs����ƍ��m���ꂽ |
| �c | 153����Name������ 25/11/25(��)21:36:15No.147855��������x2Genesis Mission�F |
| �c | 154����Name������ 25/11/26(��)04:06:31No.147887��������x3 1764097591455.png-(74124 B) 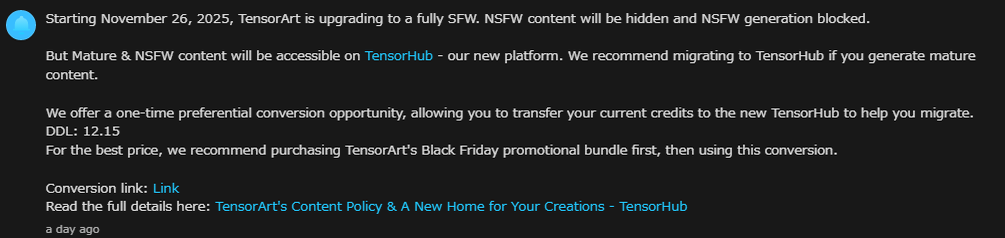 AI�v���b�g�t�H�[���T�C�gTensor.Art�͋���11��26������NSFW�摜�����E�\����S�ʔr�� |
| �c | 155����Name������ 25/11/26(��)07:53:25No.147902��������x2FLUX.2 |
| �c | 156����Name������ 25/11/27(��)00:28:12No.148023��������x2TiDAR(Think in Diffusion, Talk in Autoregression) |
| �c | 157����Name������ 25/11/28(��)08:44:18No.148124��������x1Alibaba��Tongyi-MAI����Z-IMage�Ƃ����摜����AI�������[�X |
| �c | 158����Name������ 25/11/28(��)08:47:19No.148125��������x1INTELLECT-3 |
| �c | 159����Name������ 25/11/28(��)08:57:54No.148126��������x1DeepSeek-Math-V2 |
| �c | 160����Name������ 25/11/29(�y)19:03:16No.148274��������x1AI�E�@�B�w�K����̊w�p��c�v���b�g�t�H�[�� OpenReview �̐Ǝ㐫�ɂ��A���ҁE���ǎҁE�G���A�`�F�A�̐g����R�k����Ƃ����Z�L�����e�B�C���V�f���g |
| �c | 161����Name������ 25/11/30(��)13:30:22No.148339+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 162����Name������ 25/12/01(��)04:07:50No.148417��������x2tensor��nsfw�_���ɂȂ����̂� |
| �c | 163����Name������ 25/12/01(��)20:53:52No.148470��������x1DeepSeek-V3.2��DeepSeek-V3.2-Speciale�������[�X |
| �c | 164����Name������ 25/12/02(��)00:07:09No.148491��������x1Runway����Gen-4.5�������[�X |
| �c | 165����Name������ 25/12/02(��)01:21:06No.148495��������x1 1764606066116.webp-(63754 B) 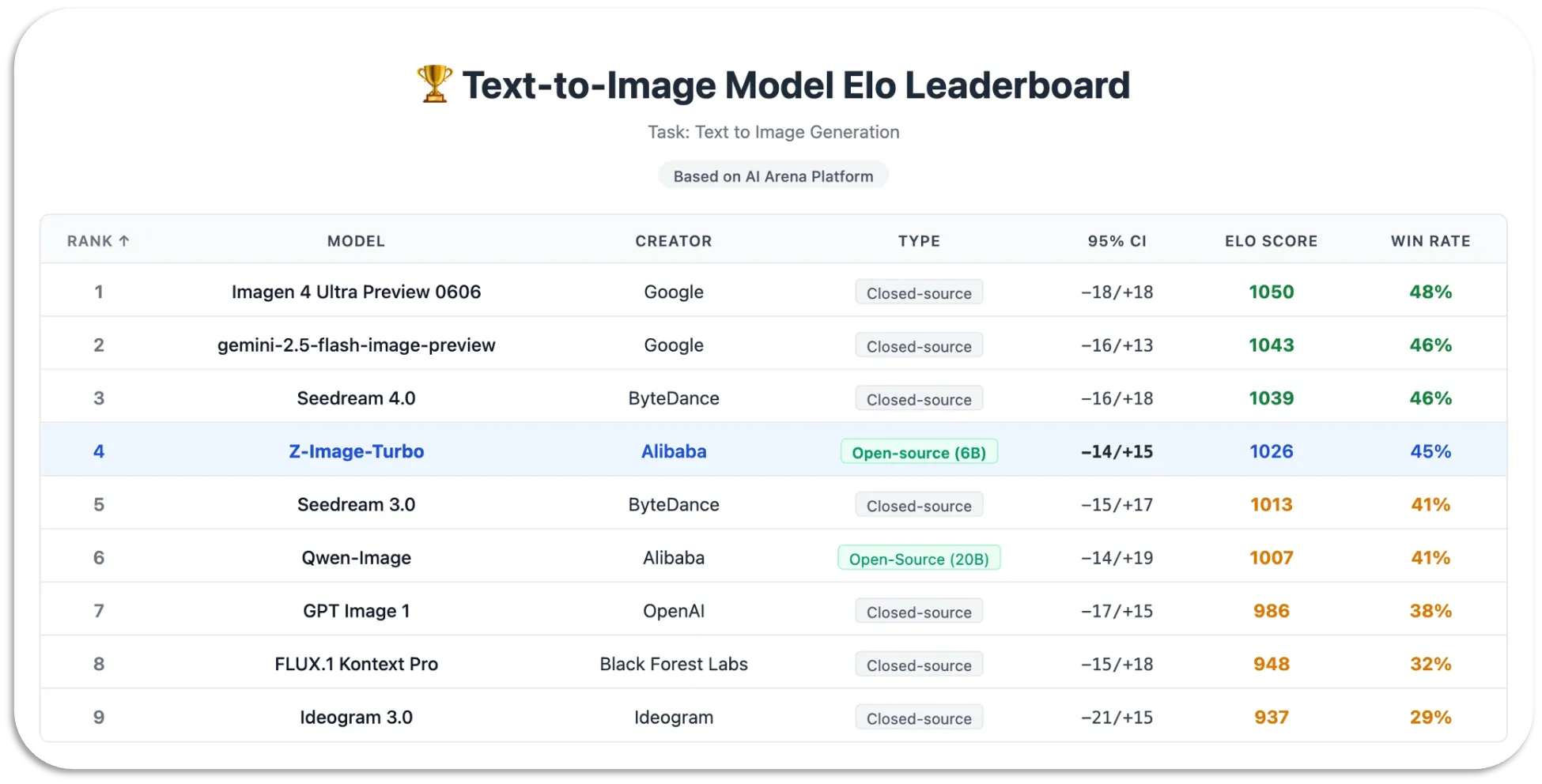 >Alibaba��Tongyi-MAI����Z-IMage�Ƃ����摜����AI�������[�X |
| �c | 166����Name������ 25/12/02(��)07:04:21No.148504��������x1Kling O1�����[���` |
| �c | 167����Name������ 25/12/02(��)18:02:19No.148525��������x1AI���y�̋}���ȐZ��: |
| �c | 168����Name������ 25/12/03(��)06:20:31No.148595��������x1STARFlow-V |
| �c | 169����Name������ 25/12/03(��)06:40:52No.148596��������x1�R���e�L�X�g�t���[�����[�N�F |
| �c | 170����Name������ 25/12/03(��)06:42:59No.148597��������x1>�R���e�L�X�g�t���[�����[�N�F |
| �c | 171����Name������ 25/12/03(��)08:21:29No.148600��������x1Mistral3 |
| �c | 172����Name������ 25/12/03(��)08:25:39No.148602��������x1Amazon����Nova2�V���[�Y |
| �c | 173����Name������ 25/12/03(��)08:28:45No.148604��������x1Kling IMAGE O1 |
| �c | 174����Name������ 25/12/04(��)00:37:03No.148671��������x1ByteDance��Seedream 4.5 |
| �c | 175����Name������ 25/12/04(��)00:41:14No.148672��������x3�S�����Ń^�X�N�����Ȃ��Ă����AI�u���E�U |
| �c | 176����Name������ 25/12/04(��)07:11:49No.148684��������x3Kling VIDEO 2.6 |
| �c | 177����Name������ 25/12/05(��)00:28:50No.148759��������x3LaViDa |
| �c | 178����Name������ 25/12/05(��)01:28:05No.148763��������x2AI���ڂ̘b��ł͂Ȃ���Micron���R���V���[�}RAM���Ƃ���P�ނ\ |
| �c | 179����Name������ 25/12/06(�y)00:40:31No.148860��������x2Gemini 3 Deep Think |
| �c | 180����Name������ 25/12/06(�y)21:59:55No.148953��������x2https://x.com/KobeissiLetter/status/1996698225399435686 |
| �c | 181����Name������ 25/12/07(��)01:26:30No.148993��������x5�����A�b�v���̂��Ƒ�����AI�͑債�ĊW�Ȃ���Ȃ����c�H |
| �c | 182����Name������ 25/12/08(��)23:06:47No.149168��������x2Z.ai����GLM-4.6V�V���[�Y�������[�X |
| �c | 183����Name������ 25/12/10(��)09:18:36No.149339��������x2Mistral����Devstral 2�i123B��24B�j�������[�X |
| �c | 184����Name������ 25/12/12(��)05:18:16No.149535��������x2GPT-5.2 |
| �c | 185����Name������ 25/12/13(�y)17:46:58No.149702��������x4 1765615618025.jpg-(636964 B)  �f�B�Y�j�[�AAI���^�h����I�[�v��AI�����Ƃɓ]�����w�i |
| �c | 186����Name������ 25/12/13(�y)21:30:34No.149720��������x3ZOOM��Gemini3��HLE�̃X�R�A�����郂�f�����J�������炵�� |
| �c | 187����Name������ 25/12/17(��)06:59:52No.150076��������x3Wan2.6 |
| �c | 188����Name������ 25/12/17(��)22:13:09No.150177��������x3 1765977189248.jpg-(685794 B)  �{������ |
| �c | 189����Name������ 25/12/19(��)09:16:39No.150341+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 190����Name������ 25/12/19(��)12:01:18No.150356+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 191����Name������ 25/12/19(��)12:02:21No.150357+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 192����Name������ 25/12/19(��)12:03:44No.150358+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 193����Name������ 25/12/19(��)12:04:53No.150359+�������݂������l�ɂ���č폜����܂��� |
| �c | 194����Name������ 25/12/19(��)12:07:38No.150360+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 195����Name������ 25/12/19(��)18:20:49No.150377+�������݂������l�ɂ���č폜����܂��� |
| �c | 196����Name������ 25/12/19(��)18:21:35No.150378+�������݂������l�ɂ���č폜����܂��� |
| �c | 197����Name������ 25/12/19(��)18:24:35No.150379��������x3Microsoft���摜����3D���f��������TRELLIS.2�����J |
| �c | 198����Name������ 25/12/20(�y)01:13:17No.150422��������x2>No.150177 |
| �c | 199����Name������ 25/12/23(��)23:26:39No.150805��������x2Gemini 3 Flash |
| �c | 200����Name������ 25/12/23(��)23:29:33No.150806��������x2Nvidia����Nemotron 3�t�@�~���[��Nano�����J |
| �c | 201����Name������ 25/12/23(��)23:31:56No.150807��������x2�y�V��Rakuten AI 3.0�����\ |
| �c | 202����Name������ 25/12/23(��)23:36:22No.150810��������x2Xiaomi����MiMo-V2-Flash�Ƃ����I�[�v�����f���������[�X |
| �c | 203����Name������ 25/12/23(��)23:38:10No.150811��������x2Meta����SAM Audio�����J |
| �c | 204����Name������ 25/12/23(��)23:41:09No.150813��������x2GPT Image 1.5 |
| �c | 205����Name������ 25/12/23(��)23:43:20No.150817��������x1Google����T5Gemma v2 |
| �c | 206����Name������ 25/12/23(��)23:51:27No.150822��������x1Microsoft����TRELLIS.2 |
| �c | 207����Name������ 25/12/23(��)23:52:50No.150823��������x2Qwen����Qwen-Image-Layered |
| �c | 208����Name������ 25/12/23(��)23:55:00No.150826��������x1GPT-5.2-Codex |
| �c | 209����Name������ 25/12/23(��)23:58:19No.150828��������x2MiniMax M2.1 |
| �c | 210����Name������ 25/12/24(��)00:02:40No.150829��������x2Z.ai����GLM-4.7�������[�X |
| �c | 211����Name������ 25/12/24(��)00:14:44No.150833��������x1Mistral OCR 3 |
| �c | 212����Name������ 25/12/24(��)00:17:51No.150834��������x1Cohere����Rerank 4 |
| �c | 213����Name������ 25/12/24(��)00:44:14No.150840��������x2�V����Qwen3-TTS�Ƃ���VoiceDesign��VoiceClone�������[�X |
| �c | 214����Name������ 25/12/24(��)04:06:21No.150852+�������݂������l�ɂ���č폜����܂��� |
| �c | 215����Name������ 25/12/24(��)04:07:22No.150853��������x21913�N�ȑO�̃f�[�^�݂̂ō\�z���ꂽAI�uRanke-4B�v |
| �c | 216����Name������ 25/12/24(��)06:28:42No.150855��������x2Qwen-Image-Edit-2511 |
| �c | 217����Name������ 25/12/24(��)06:37:30No.150856��������x2Bytedance����Seedance 1.5 pro�������[�X |
| �c | 218����Name������ 25/12/29(��)01:31:50No.151379��������x3 1766939510877.mp4-(2267553 B)  �[圳�Ńq���[�}�m�C�h�^�̃��{�b�g�x���� |
| �c | 219����Name������ 25/12/30(��)04:13:46No.151531��������x4https://arxiv.org/abs/2512.14982 |
| �c | 220����Name������ 25/12/30(��)17:38:28No.151589��������x2�݂��ً�s�AAI�u�[���̃��X�N�V�i���I |
| �c | 221����Name������ 25/12/31(��)21:09:42No.151754��������x3���̊Ԃ�Edit-2511�ɑ����č��xQwen-Image-2512 |
| �c | 222����Name������ 26/01/03(�y)02:19:47No.152066��������x2AIVtuver��Neuro-sama�Č����߂��������|�W�g���̏Љ� |
| �c | 223����Name������ 26/01/03(�y)23:49:16No.152149��������x4�������ߍ��N���j���[�X��낵���� |
| �c | 224����Name������ 26/01/05(��)21:46:04No.152385��������x3https://github.com/ahujasid/blender-mcp |
| �c | 225����Name������ 26/01/06(��)20:46:05No.152494��������x2bitnet.cpp���I�[�v���\�[�X�� |
| �c | 226����Name������ 26/01/07(��)02:00:59No.152538��������x2PlayStation�����uAI�S�[�X�g�v�������\�j�[���o��BAI������ɃQ�[�����N���A |
| �c | 227����Name������ 26/01/07(��)15:59:24No.152564��������x2LTX�r�f�I��Ver2.0 |
| �c | 228����Name������ 26/01/07(��)16:14:49No.152565��������x4�l�Ԃɂ��R�[�f�B���O�Ƃ����s�ׂ��߂������Ȃ��Ȃ� |
| �c | 229����Name������ 26/01/07(��)16:41:15No.152566��������x2claude-mem |
| �c | 230����Name������ 26/01/07(��)16:52:54No.152567��������x3higgsfield Relight |
| �c | 231����Name������ 26/01/08(��)12:09:56No.152644��������x1Tencent��Hunyuan�`�[�����I�[�v���\�[�X�̃��A���^�C�����E���f���uHY World 1.5�v�����[�X |
| �c | 232����Name������ 26/01/09(��)04:31:52No.152685��������x2Apple Sharp/Monocular View Synthesis |
| �c | 233����Name������ 26/01/09(��)04:42:51No.152686��������x2xAI�̌����G���W�j�AMiao���ɂ��AITuber�hMIA�h |
| �c | 234����Name������ 26/01/09(��)06:31:22No.152687��������x3 1767907882222.webp-(76724 B) 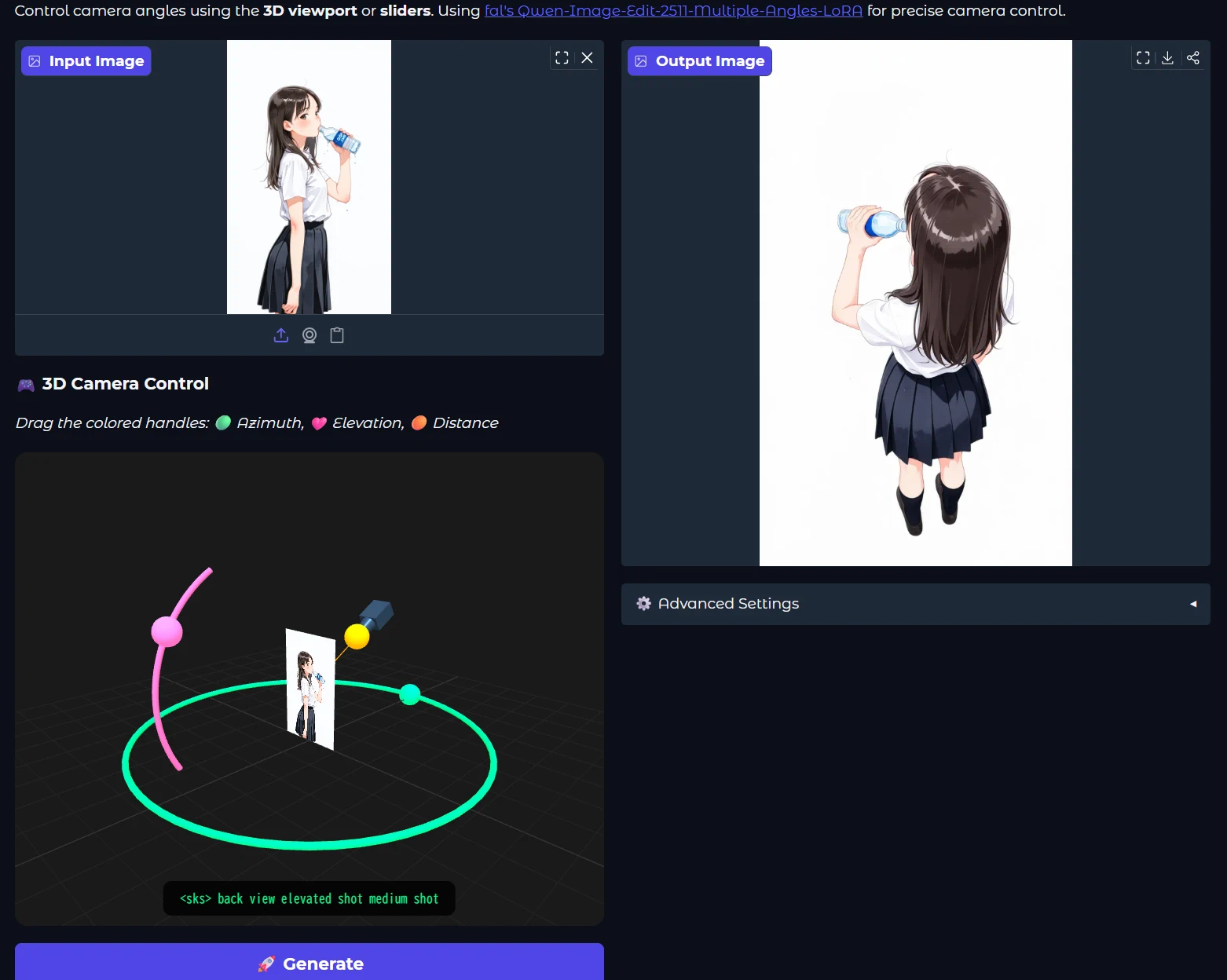 Qwen Image Multiple Angles 3D Camera |
| �c | 235����Name������ 26/01/09(��)17:36:41No.152719��������x3�������Cygames�A������ЁuCygames AI Studio�v��ݗ� |
| �c | 236����Name������ 26/01/09(��)17:47:24No.152721��������x3 1767948444044.png-(675807 B) 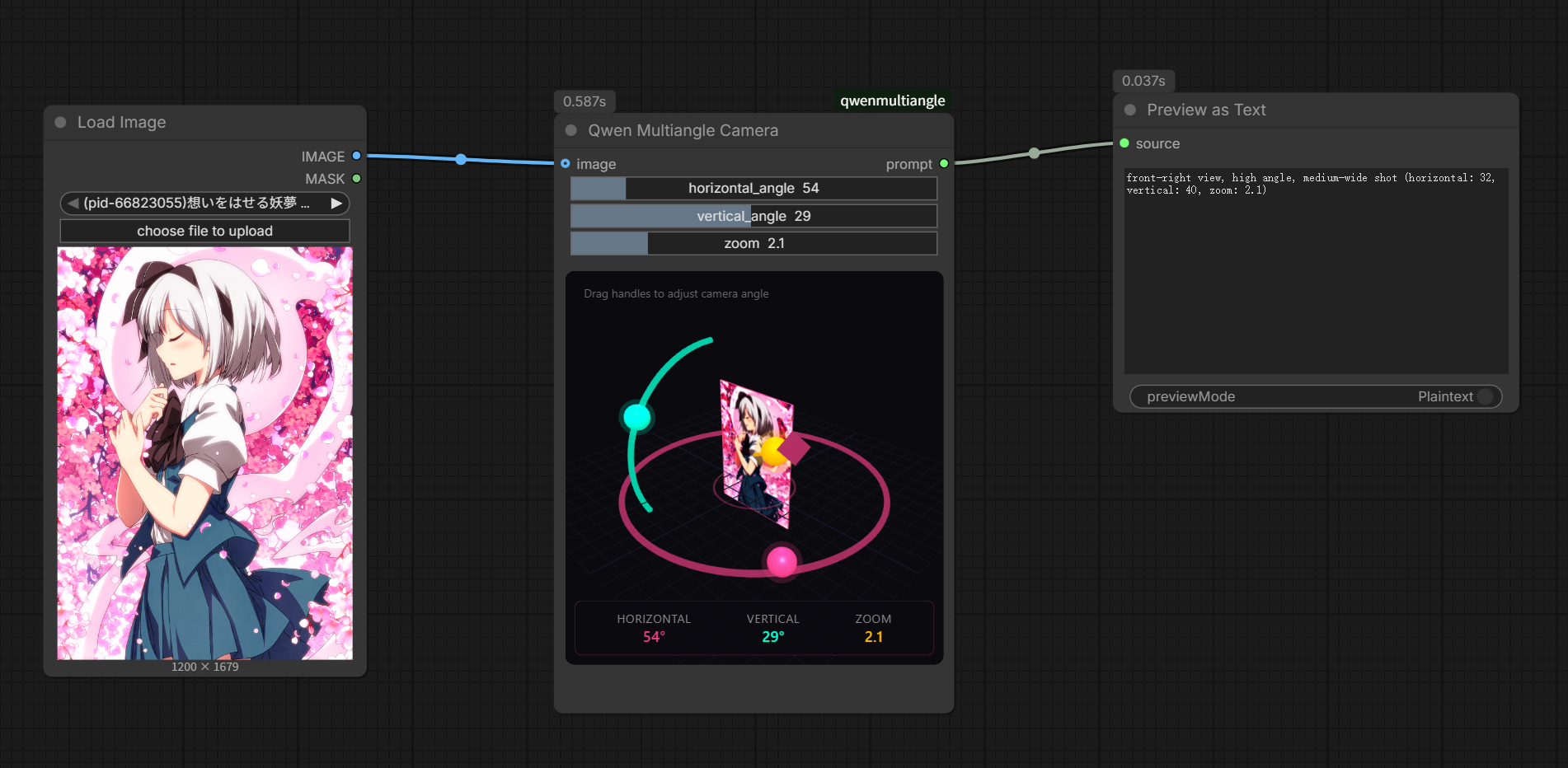 >Qwen Image Multiple Angles 3D Camera |
| �c | 237����Name������ 26/01/10(�y)04:40:01No.152759��������x3>LTX�r�f�I��Ver2.0 |
| �c | 238����Name������ 26/01/10(�y)09:36:42No.152767��������x5Niji 7 - niji journey ver.7�����[�X |
| �c | 239����Name������ 26/01/10(�y)16:11:55No.152785��������x3>Niji 7 - niji journey ver.7�����[�X |
| �c | 240����Name������ 26/01/11(��)00:56:59No.152839��������x4�R�~�b�N�V�[���A�ŤAI���悪�ǎғ��[��1�ʂ���� |
| �c | 241����Name������ 26/01/11(��)08:16:02No.152857��������x1�j���[�����C�c�iNeuroRights�j�Ƃ�? |
| �c | 242����Name������ 26/01/11(��)12:26:10No.152882��������x2Qwen3-VL-Embedding��Qwen3-VL-Reranker |
| �c | 243����Name������ 26/01/11(��)12:32:58No.152883��������x4Liquid AI��LFM2.5-1.2B�t�@�~���[ |
| �c | 244����Name������ 26/01/12(��)19:01:56No.153023��������x5 1768212116433.mp4-(8031961 B)  �g�قڐ���AI�h���̃~���[�W�b�N�r�f�I���}�㏸�@�e�ڂ��̊y�ȁu�J��ҁv�ɒ��� |
| �c | 245����Name������ 26/01/15(��)02:41:31No.153249��������x5 1768412491283.jpg-(333301 B)  AI������i��������܂��l�������Љ����~ |
| �c | 246����Name������ 26/01/15(��)22:51:44No.153308��������x4�Z�b�V�����n�C�W���b�N�uReprompt�v |
| �c | 247����Name������ 26/01/19(��)08:27:52No.153554��������x3�C�[�����}�X�N��OpenAI��1340���h���Œ�i |
| �c | 248����Name������ 26/01/19(��)23:45:55No.153602��������x3AMD Radeon��ROCm��v7.1.1 |
| �c | 249����Name������ 26/01/20(��)11:55:08No.153639��������x4Beyond Max Tokens: |
| �c | 250����Name������ 26/01/21(��)00:16:06No.153678��������x2>HIP�iHeterogeneous-compute Interface for Portability�j�Ƃ����݊����C���[��ʂ��āACUDA�R�[�h��AMD GPU��œ��삳���邱�Ƃ��ł��܂��B |
| �c | 251����Name������ 26/01/21(��)01:48:13No.153682��������x2ROCm���̂��̂̎d�g�݂ł͂Ȃ����ǂ� |
| �c | 252����Name������ 26/01/21(��)10:13:24No.153702��������x5ROCm�͊J���v���b�g�t�H�[���S�̖̂��́AHIP�͂ق�CUDA�Ɠ����R�[�h�œ�������AMD/NVIDIA���Ή��Ȍ݊�API�iC/C++�g���j�ł���A���ԃR�[�h�ł���LLVM IR������ |
| �c | 253����Name������ 26/01/22(��)13:34:32No.153788��������x5airLLM |
| �c | 254����Name������ 26/01/25(��)01:44:36No.153960��������x3Vision-as-Inverse-Graphics Agent |
| �c | 255����Name������ 26/01/26(��)12:03:07No.154060��������x2Google�A�摜�������f���Nano Banana Pro����X�^�[�g�@�@ |
| �c | 256����Name������ 26/02/01(��)00:33:47No.154438��������x2OpenAI��Nvidia�̋������̒���H |
| �c | 257����Name������ 26/02/01(��)23:43:43No.154535��������x2https://www.nikkei.com/article/DGXZQOGN0109X0R00C26A2000000/ |
| �c | 258����Name������ 26/02/04(��)00:34:51No.154734��������x2https://rentahuman.ai/ |
| �c | 259����Name������ 26/02/04(��)01:41:57No.154736��������x3https://gigazine.net/news/20260203-grok-imagine-video-generation-ai/ |
| �c | 260����Name������ 26/02/09(��)00:50:21No.155053��������x2Anthropic���uOpus 4.6���g���AClaude Code��16�̃`�[���ŕ���ɑ��点�āA�l�Ԃ��قډ��������Rust����C�R���p�C�����[������\�z�B�v |
| �c | 261����Name������ 26/02/09(��)16:47:11No.155100��������x2>No.154734 |
| �c | 262����Name������ 26/02/10(��)19:45:17No.155212+�������݂������l�ɂ���č폜����܂��� |
| �c | 263����Name������ 26/02/10(��)19:47:34No.155213��������x2Bytedance�����搶��AI�uSeedance 2.0�v�\ |
| �c | 264����Name������ 26/02/15(��)07:16:05No.155530��������x2MACROHARD project |
| �c | 265����Name������ 26/02/15(��)20:08:16No.155574��������x2�\�j�[�O���[�v�A���AI�̊w�K�f�[�^�����@�n��҂ւ̑Ή��Z�o�\�Ɂi�L���L���j |
| �c | 266����Name������ 26/02/17(��)01:23:05No.155660��������x1ComfyUI��GPU�}�����ĕ��ו��U������@�̎��H�I�ȃX���b�h |
| �c | 267����Name������ 26/02/17(��)23:13:14No.155723��������x1 1771337594061.jpg-(74162 B)  https://www.spacemolt.com/ |
| �c | 268����Name������ 26/02/20(��)19:02:25No.155936��������x2�����Ȋw��w��H�w�@�̉��茤�����Ɖ��c�������A���������J���@�l�Y�ƋZ�p�����������̌����`�[����GPT-OSS Swallow �� Qwen3 Swallow �������[�X���܂����B |
| �c | 269����Name������ 26/02/20(��)19:07:39No.155937��������x1 1771582059686.jpg-(38912 B)  NVIDIA�́A90���p�����[�^�̌��ꃂ�f���uNVIDIA Nemotron-Nano-9B-v2-Japanese�v�����J�����B���p���p���\ |
| �c | 270����Name������ 26/02/20(��)19:26:05No.155941��������x2https://huggingface.co/TeichAI/Qwen3-14B-Claude-4.5-Opus-High-Reasoning-Distill-GGUF |
| �c | 271����Name������ 26/02/21(�y)00:46:39No.155990��������x2Kitten TTS V0.8: |
| �c | 272����Name������ 26/02/21(�y)09:51:17No.156008��������x2Taalas�� �̃A�v���[�`�FHardcore Models |
| �c | 273����Name������ 26/02/21(�y)10:40:22No.156010��������x2openrouter�̃g�[�N���ʂ��猩��LLM�g�p�����L���O |
| �c | 274����Name������ 26/02/22(��)10:25:12No.156097��������x1>https://www.spacemolt.com/ |
| �c | 275����Name������ 26/02/23(��)02:12:31No.156185��������x3�A�C���V���^�C���E�e�X�g�i1911�N�J�b�g�I�t�E�e�X�g�j |
| �c | 276����Name������ 26/02/23(��)02:18:35No.156187��������x2�Q�[���w�K��LLM���l������ĉ��\�� |
| �c | 277����Name������ 26/02/27(��)13:06:42No.156567+�X���b�h�𗧂Ă��l�ɂ���č폜����܂��� |
| �c | 278����Name������ 26/03/20(��)16:55:47No.158360��������x2 1773993347468.jpg-(353054 B) 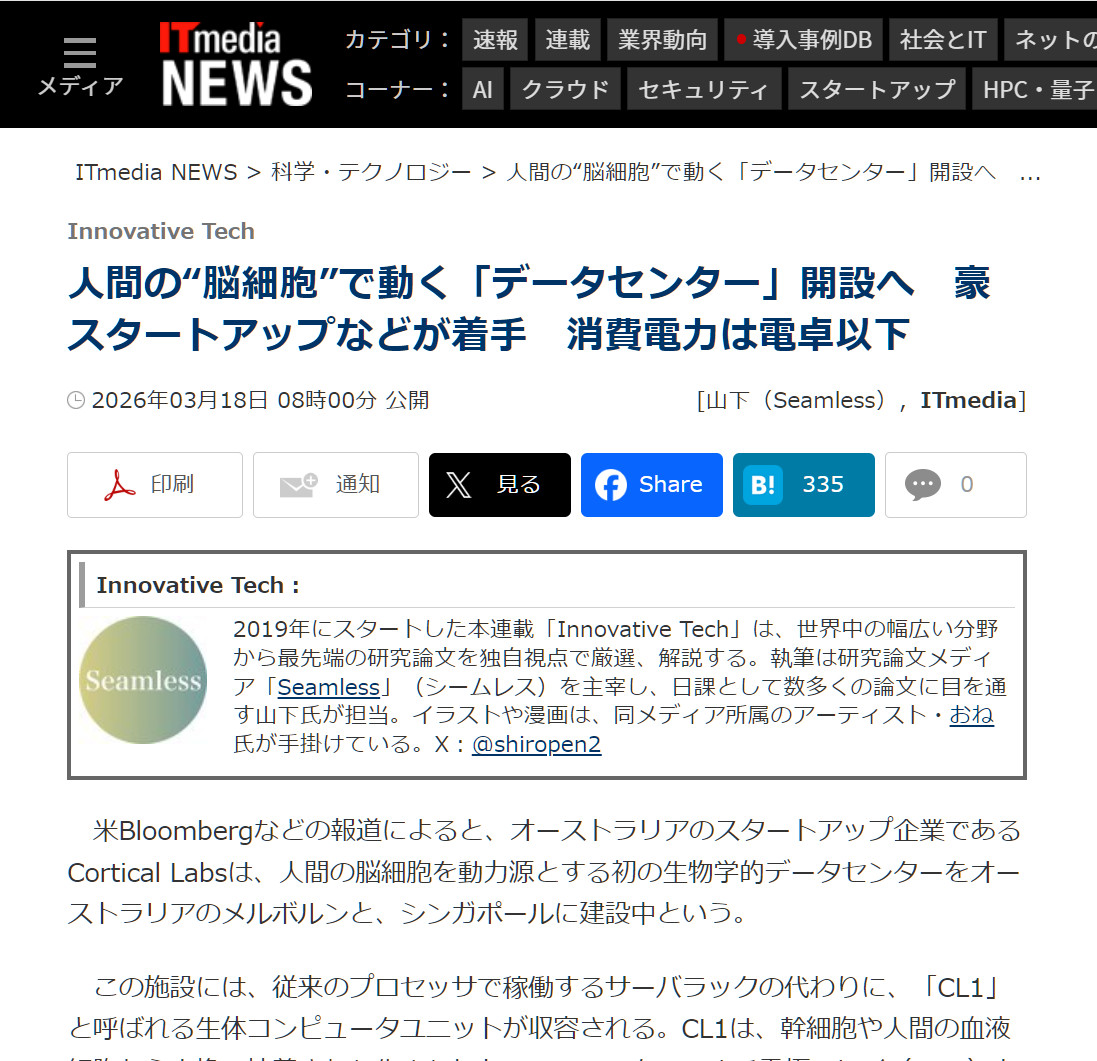 �l�Ԃ́g�]�זE�h�œ����u�f�[�^�Z���^�[�v�J�݂ց@���X�^�[�g�A�b�v�Ȃǂ�����@����d�͓͂d��ȉ� |
| �c | 279����Name������ 26/03/23(��)16:45:22No.158578��������x3�Ȃ|���� |
| �c | 280����Name������ 26/03/25(��)11:53:35No.158684��������x3OpenAI�A�uSora�v�I���� |
| �c | 281����Name������ 26/03/25(��)12:47:39No.158691��������x1�}�W�� |
| �c | 282����Name������ 26/03/25(��)13:26:00No.158693+�I���̑����˂� |
| �c | 283����Name������ 26/03/25(��)16:47:44No.158701��������x1����ϐ푈���ăN�\���� |
| �c | 284����Name������ 26/03/31(��)12:21:20No.159206+ 1774927280680.jpg-(317989 B)  Claude�̃R�[�h�ͤClaude�������Ă��� |
| �c | 285����Name������ 26/03/31(��)17:08:41No.159217+ 1774944521546.jpg-(197562 B) 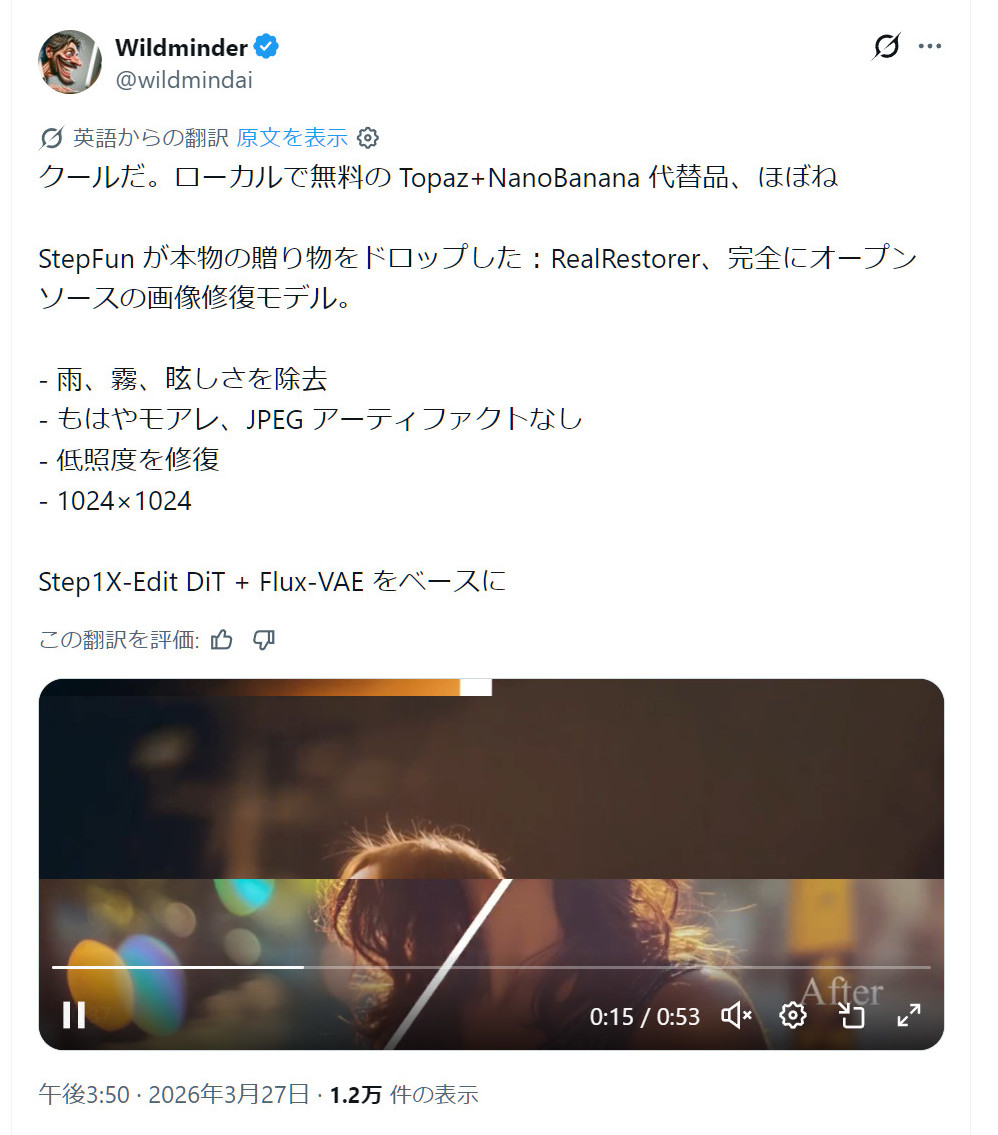 �y�����̖����摜�C���z�ŐV���f���wRealRestorer�x����������I |